
目录
1. 常量池
1.1 Class 常量池
1.2 运行时常量池
2. 字符串常量池
2.1 字符串常量池设计思想
2.2 三种字符串的操作(JDK1.7及以上版本)
2.3 字符串常量池位置
2.4 字符串常量池设计原理
2.5 String常量池分析示例
3. 八种基本类型的包装类和对象池
1. 常量池
1.1 Class 常量池
Class常量池可以理解为是Class文件中的资源仓库。 Class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic References)。
下图中字节码指令文件中的constant pool就是class 常量池,主要存放字面量和符号引用。
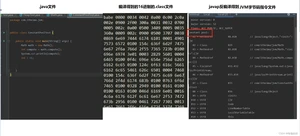
字面量
字面量就是指由字母、数字等构成的字符串或者数值常量。
字面量只可以右值出现,所谓右值是指等号右边的值
如:int a=1 这里的a为左值,1为右值。在这个例子中1就是字面量。
符号引用
符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
上面的i、ompute、math就是字段名称,就是一种符号引用,com.test.jvm是类的全限定名,main是方法名称,()是一种UTF8格式的描述符,这些都是符号引用。
1.2 运行时常量池
Class 常量池是.java文件编译后的静态信息,当这些信息到运行时被加载到内存后,这些符号才有对应的内存地址信息,这些常量池一旦被装入内存就变成运行时常量池,对应的符号引用在程序加载或运行时会被转变为被加载到内存区域的代码的直接引用,也就是我们说的动态链接了。例如,compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址,主要通过对象头里的类型指针去转换直接引用。
2. 字符串常量池
2.1 字符串常量池设计思想
- 字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。
- JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。
- 为字符串开辟一个字符串常量池,类似于缓存区。
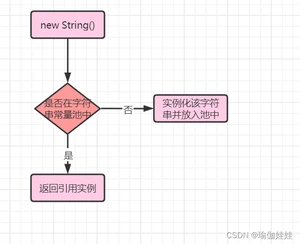
- 创建字符串常量时,首先查询字符串常量池是否存在该字符串。
- 存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中。
2.2 三种字符串的操作(JDK1.7及以上版本)
直接赋值字符串
这种方式创建的字符串对象,只会在常量池中。
因为有"zhnangSan"这个字面量,创建对象s的时候,JVM会先去常量池中通过 equals(key) 方法,判断是否有相同的对象
如果有,则直接返回该对象在常量池中的引用;
如果没有,则会在常量池中创建一个新对象,再返回引用。
new String();
这种方式会保证字符串常量池和堆中都有这个对象,没有就创建,最后返回堆内存中的对象引用。
步骤大致如下:
因为有"zhangsan"这个字面量,所以会先检查字符串常量池中是否存在字符串"zhangsan"
不存在,先在字符串常量池里创建一个字符串对象;再去内存中创建一个字符串对象"zhangsan";
存在的话,就直接去堆内存中创建一个字符串对象"zhangsan";
最后,将内存中的引用返回。
intern方法
String中的intern方法是一个 native 的方法,当调用 intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(oject)方法确定),则返回池中的字符串。否则,将intern返回的引用指向当前字符串 s1(jdk1.6版本需要将 s1 复制到字符串常量池里)。
2.3 字符串常量池位置
- Jdk1.6及之前: 有永久代, 运行时常量池在永久代,运行时常量池包含字符串常量池。
- Jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池从永久代里的运行时常量池分离到堆里。
- Jdk1.8及之后: 无永久代,运行时常量池在元空间,字符串常量池里依然在堆里。
2.4 字符串常量池设计原理
字符串常量池底层是hotspot的C++实现的,底层类似一个 HashTable, 保存的本质上是字符串对象的引用。
示例:
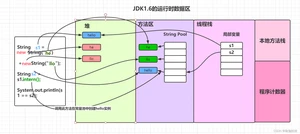
上面示例中为什么在不同版本下同样的代码会有不一样的结果呢?主要还是字符串池从永久代中脱离、移入堆区的原因, intern() 方法也相应发生了变化,接下来我们从jdk不同版本JVM的运行时数据区来分析下一。
1、在 JDK 1.6 中,调用 intern() 首先会在字符串池中寻找 equal() 相等的字符串,假如字符串存在就返回该字符串在字符串池中的引用;假如字符串不存在,虚拟机会重新在永久代上创建一个实例,将 StringTable 的一个表项指向这个新创建的实例。
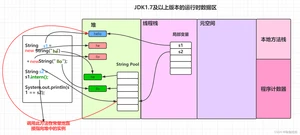
2、在 JDK 1.7 (及以上版本)中,由于字符串池不在永久代了,intern() 做了一些修改,更方便地利用堆中的对象。字符串存在时和 JDK 1.6一样,但是字符串不存在时不再需要重新创建实例,可以直接指向堆上的实例。
2.5 String常量池分析示例
注意:以下示例都是基于jdk1.7及以上版本讨论的
示例1:
分析:因为例子中的 s0和s1中的”zhangsan”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而”zhang”和”san”也都是字符串常量,当一个字 符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被优化为一个字符串常量"zhangsan",所以s2也是常量池中” zhangsan”的一个引用。所以我们得出s0==s1==s2;
示例2:
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
s0还是常量池 中"zhangsan”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象”zhangsan”的引用,s2因为有后半部分 new String(”san”)所以也无法在编译期确定,所以也是一个新创建对象”zhangsan”的引用;明白了这些也就知道为何得出此结果了。
示例3:
分析:JVM对于字符串常量的"+"号连接,将在程序编译期,JVM就将常量字符串的"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。在编译期其字符串常量的值就确定下来,故上面程序最终的结果都为true。
示例4:
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面程序的结果也就为false。
示例5:
分析:和示例4中唯一不同的是bb字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是一样的。故上面程序的结果为true。
示例6:
分析:JVM对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b,故上面 程序的结果为false。
示例7:
3. 八种基本类型的包装类和对象池
java中基本类型的包装类的大部分都实现了常量池技术(严格来说应该叫对象池,在堆上),这些类是Byte,Short,Integer,Long,Character,Boolean,另外两种浮点数类型的包装类则没有实现。另外Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对java常量池基础知识应值小于等于127时才可使用对象池,也即对象不负责创建和管理大于127的这些类的对象。因为一般这种比较小的数用到的概率相对较大。
示例:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/18708.html