
并发编程领域的任务可以分为三种:简单并行任务、聚合任务和批量并行任务,见下图。
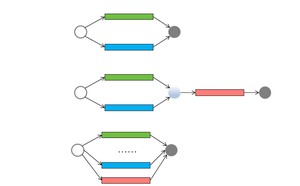
这些模型之外,还有一种任务模型被称为“分治”。分治是一种解决复杂问题的思维方法和模式;具体而言,它将一个复杂的问题分解成多个相似的子问题,然后再将这些子问题进一步分解成更小的子问题,直到每个子问题变得足够简单从而可以直接求解。
从理论上讲,每个问题都对应着一个任务,因此分治实际上就是对任务的划分和组织。分治思想在许多领域都有广泛的应用。例如,在算法领域,我们经常使用分治算法来解决问题(如归并排序和快速排序都属于分治算法,二分查找也是一种分治算法)。在大数据领域,MapReduce 计算框架背后的思想也是基于分治。
由于分治这种任务模型的普遍性,Java 并发包提供了一种名为 Fork/Join 的并行计算框架,专门用于支持分治任务模型的应用。
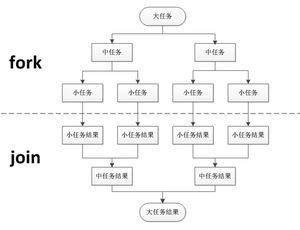
分治任务模型可分为两个阶段:一个阶段是 任务分解,就是迭代地将任务分解为子任务,直到子任务可以直接计算出结果;另一个阶段是 结果合并,即逐层合并子任务的执行结果,直到获得最终结果。下图是一个简化的分治任务模型图,你可以对照着理解。
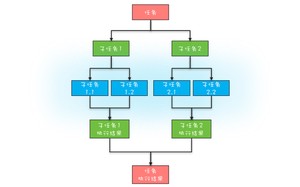
在这个分治任务模型里,任务和分解后的子任务具有相似性,这种相似性往往体现在任务和子任务的算法是相同的,但是计算的数据规模是不同的。具备这种相似性的问题,我们往往都采用递归算法。
Fork/Join 是一个并行计算框架,主要用于支持分治任务模型。在这个计算框架中,Fork 代表任务的分解,而 Join 代表结果的合并。
Fork/Join 计算框架主要由两部分组成:分治任务的线程池 ForkJoinPool 和分治任务 ForkJoinTask。
这两部分的关系类似于 ThreadPoolExecutor 和 Runnable 之间的关系,都是用于提交任务到线程池的,只不过分治任务有自己独特的类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,其中有许多方法,其中最核心的是 方法和 方法。fork 方法用于异步执行一个子任务,而 join 方法通过阻塞当前线程来等待子任务的执行结果。
ForkJoinTask 有两个子类:RecursiveAction 和 RecursiveTask。
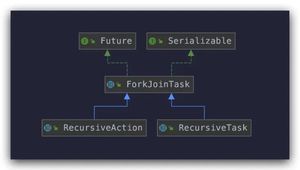
从它们的名字就可以看出,都是通过递归的方式来处理分治任务的。这两个子类都定义了一个抽象方法 ,不同之处在于 RecursiveAction 的 compute 方法没有返回值,而 RecursiveTask 的 compute 方法有返回值。这两个子类也都是抽象类,在使用时需要创建自定义的子类来扩展功能。
接下来,让我们使用 Fork/Join 并行计算框架来计算斐波那契数列(下面的代码示例源自 Java 官方示例)。
首先,我们需要创建一个 ForkJoinPool 线程池以及一个用于计算斐波那契数列的 Fibonacci 分治任务。然后,通过调用 ForkJoinPool 线程池的 方法来启动分治任务。
由于计算斐波那契数列需要返回结果,所以我们的 Fibonacci 类继承自 RecursiveTask。Fibonacci 分治任务需要实现 compute 方法,在这个方法中,逻辑与普通计算斐波那契数列的方法非常相似,只是在计算 时使用了异步子任务,这是通过 语句来实现。
运行程序,我们会得到如下的结果:
Fork/Join 并行计算的核心组件是 ForkJoinPool。下面简单介绍一下 ForkJoinPool 的工作原理。
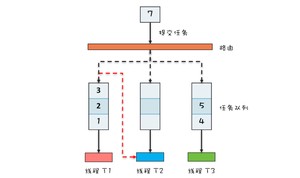
当我们通过 ForkJoinPool 的 invoke 或 submit 方法提交任务时,ForkJoinPool 会根据一定的路由规则将任务分配到一个任务队列中。如果任务执行过程中创建了子任务,那么子任务会被提交到对应工作线程的任务队列中。
ForkJoinPool 中有一个数组形式的成员变量 ,其对应一个队列数组,每个队列对应一个消费线程。丢入线程池的任务,根据特定规则进行转发。
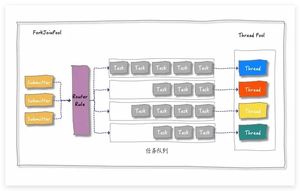
当工作线程的任务队列为空时,它是否无事可做呢?
不是的。ForkJoinPool 引入了一种称为"任务窃取"的机制。当工作线程空闲时,它可以从其他工作线程的任务队列中"窃取"任务。
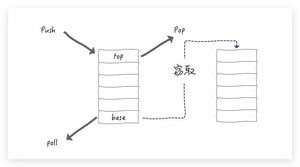
例如,下图中线程 T2 的任务队列已经为空,它可以窃取线程 T1 任务队列中的任务。这样,所有的工作线程都能保持忙碌的状态。
ForkJoinPool 中的任务队列采用双端队列的形式。工作线程从任务队列的一个端获取任务,而"窃取任务"从另一端进行消费。这种设计能够避免许多不必要的数据竞争。
ForkJoinPool 与 ThreadPoolExecutor 有很多相似之处,例如都是线程池,都是用于执行任务的。但是,它们之间也有很多不同之处。
首先,ForkJoinPool 采用的是"工作窃取"的机制,而 ThreadPoolExecutor 采用的是"工作复用"的机制。这两种机制各有优劣,ForkJoinPool 的优势在于能够充分利用 CPU 的多核能力,而 ThreadPoolExecutor 的优势在于能够避免线程间的上下文切换。
其次,ForkJoinPool 采用的是分治任务模型,而 ThreadPoolExecutor 采用的是简单并行任务模型。这两种任务模型各有优劣,ForkJoinPool 的优势在于能够处理分治任务,而 ThreadPoolExecutor 的优势在于能够处理简单并行任务。
最后,ForkJoinPool 采用的是 LIFO 的任务队列,而 ThreadPoolExecutor 采用的是 FIFO 的任务队列。这两种任务队列各有优劣,ForkJoinPool 的优势在于能够避免数据竞争,而 ThreadPoolExecutor 的优势在于能够保证任务的顺序性。
假设:我们要计算 1 到 1 亿的和,为了加快计算的速度,我们自然想到算法中的分治原理,将 1 亿个数字分成 1 万个任务,每个任务计算 1 万个数值的综合,利用 CPU 的并发计算性能缩短计算时间。
由于 ThreadPoolExecutor 可以通过 Future 获取到执行结果,因此利用 ThreadPoolExecutor 也是可行的。
当然 ForkJoinPool 实现也是可以的。下面我们将这两种方式都实现一下,看看这两种实现方式有什么不同。
无论哪种实现方式,其大致思路都是:
- 按照线程池里线程个数 N,将 1 亿个数划分成 N 等份,随后丢入线程池进行计算。
- 每个计算任务使用 Future 接口获取计算结果,最后积加即可。
我们先使用 ThreadPoolExecutor 实现。
首先,定义一个 Calculator 接口,表示计算数字总和这个动作,如下所示。
接着,我们定义一个使用 ThreadPoolExecutor 线程池实现的类,如下所示。
如上面代码所示,我们实现了一个计算单个任务的类 SumTask,在该类中对数值进行累加。其次,我们在 方法中,对 1 亿的数字进行拆分,接着扔给线程池计算,最后阻塞等待计算结果,最终累加起来。
我们运行上面的代码,可以得到顺利得到最终结果,如下所示。
接着我们使用 ForkJoinPool 来实现。
我们首先实现 SumTask 继承 RecursiveTask 抽象类,并在 compute 方法中定义拆分逻辑及计算。最后在 sumUp 方法中调用 pool 方法进行计算,代码如下所示。
运行上面的代码,结果为:
对比 ThreadPoolExecutor 和 ForkJoinPool 这两者的实现,可以发现它们都有任务拆分的逻辑,以及最终合并数值的逻辑。但 ForkJoinPool 相比 ThreadPoolExecutor 来说,做了一些实现上的封装,例如:
- 不用手动去获取子任务的结果,而是使用 join 方法直接获取结果。
- 将任务拆分的逻辑,封装到 RecursiveTask 实现类中,而不是**在外。
因此对于没有父子任务依赖,但是希望获取到子任务执行结果的并行计算任务,就可以使用 ForkJoinPool 来实现。在这种情况下,使用 ForkJoinPool 实现更多是代码实现方便,封装做得更加好。
MapReduce 是一个编程模型,同时也是一个处理和生成大数据集的处理框架。它源于 Google,用于支持在大型数据集上的分布式计算。这个框架主要由两个步骤组成:Map 步骤和 Reduce 步骤,这也是它名字的由来。
Fork/Join 并行计算框架通常被用来实现学习 MapReduce 的入门程序,该程序用于统计文件中每个单词的数量。
首先,我们可以使用二分法递归地将文件拆分为更小的部分,直到每个部分只有一行数据。然后,在每个部分中统计单词的数量,并逐级汇总结果。你可以参考之前提到的简化版分治任务模型图来理解该过程。
现在,让我们开始实现。下面的代码使用了字符串数组来模拟文件内容,其中每个元素与文件中的行数据一一对应。关键代码位于方法中,这是一个递归方法。它将前半部分数据 fork 一个递归任务进行处理(关键代码:),而后半部分数据在当前任务中递归处理()。
这个示例程序是对 Fork/Join 模型的简化,实际上在真正的 MapReduce 框架中,还涉及到数据划分、映射阶段、归约阶段等更多的步骤。但是通过此示例,大家可以初步了解如何使用 Fork/Join 并行计算框架来处理类似的任务。
Fork/Join 并行计算框架主要解决的是分治任务。分治的核心思想是“分而治之”:将一个大的任务拆分成小的子任务去解决,然后再把子任务的结果聚合起来从而得到最终结果。这个过程非常类似于大数据处理中的 MapReduce,所以你可以把 Fork/Join 看作单机版的 MapReduce。
Fork/Join 并行计算框架的核心组件是 ForkJoinPool。ForkJoinPool 支持任务窃取机制,能够让所有线程的工作量基本均衡,不会出现有的线程很忙,而有的线程很闲的状况,所以性能很好。
Java 1.8 提供的 Stream API 里面并行流也是以 ForkJoinPool 为基础的。不过需要注意的是,默认情况下所有的并行流计算都共享一个 ForkJoinPool,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。
所以 建议用不同的 ForkJoinPool 执行不同类型的计算任务。
编辑:沉默王二,部分内容来源于这篇文章:分而治之思想Forkjoin,还有一部分内容来源于朋友陈树义的这篇文章,内容很顶,强烈推荐。还有一部分图片来自于朋友「日拱一兵」的文章。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第二份 PDF 《并发编程小册》终于来了!包括线程的基本概念和使用方法、Java的内存模型、sychronized、volatile、CAS、AQS、ReentrantLock、线程池、并发容器、ThreadLocal、生产者消费者模型等面试和开发必须掌握的内容,共计 15 万余字,200+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,二哥的并发编程进阶之路.pdf
加入二哥的编程星球,在星球的第二个置顶帖「知识图谱」里就可以获取 PDF 版本。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/12401.html