
Hadoop简介
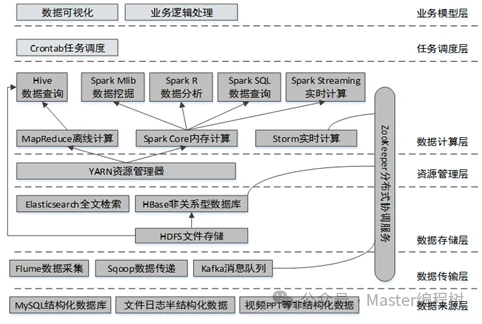
Apache Hadoop是大数据开发所使用的一个核心框架,是一个允许使用简单编程模型跨计算机集群分布式处理大型数据集的系统。使用Hadoop可以方便的管理分布式集群,将海量数据分布式的存储在集群中,并使用分布式并行程序来处理这些数据。它被设计成从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。Hadoop本身的设计目的不是依靠硬件来提供高可用性,而是在应用层检测和处理故障。Hadoop的生态系统主要组成架构,如图
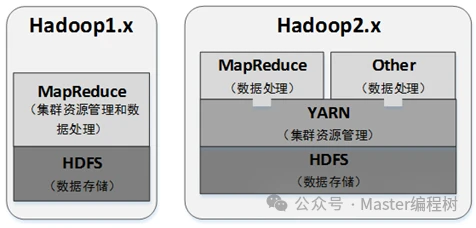
Hadoop1.x与2.x的架构对比:
以YARN为中心的共享集群资源架构:
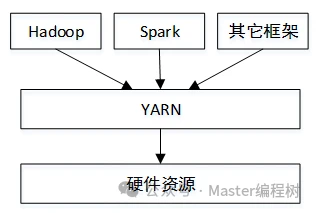
YARN其实是一个通用的资源管理系统,所谓资源管理,就是按照一定的策略将资源(内存、CPU)分配给各个应用程序使用,并且会采取一定的隔离机制防止应用程序之间彼此抢占资源而相互干扰。
YARN基本架构及组件
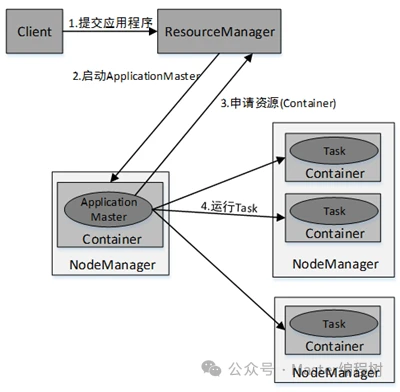
YARN集群总体上是经典的主/从(Master/Slave)架构,主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
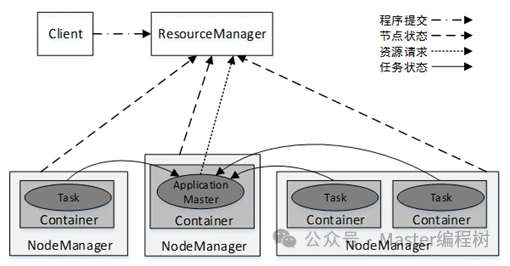
YARN集群中应用程序的执行流程如图
搭建Hadoop2.x分布式集群
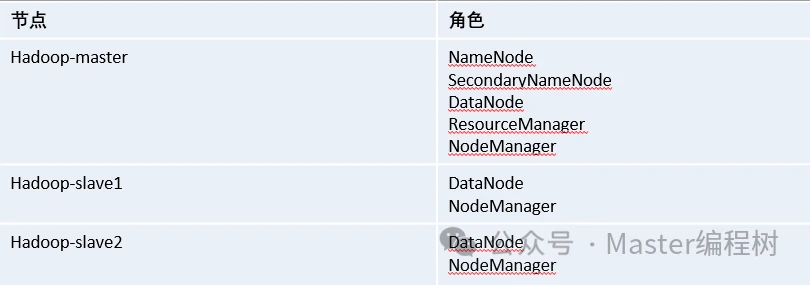
本例的搭建思路是,在节点centos01中安装Hadoop并修改配置文件,然后将配置好的Hadoop安装文件远程拷贝到集群中的其它节点。集群各节点的角色分配如表
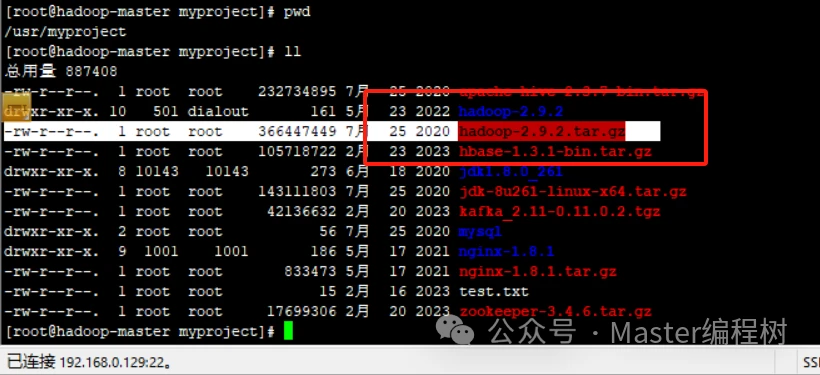
第一步:将hadoop-2.9.2.tar.gz拷贝到指定目录,解压并
第二步:配置系统环境变量
为了可以方便的在任意目录下执行Hadoop命令,而不需要进入到Hadoop安装目录,需要配置Hadoop系统环境变量。此处只需要配置centos01节点即可。
执行以下命令,修改文件/etc/profile:
在文件末尾加入以下内容:
source /etc/profile
执行hadoop命令,若能成功输出以下返回Hadoop版本信息,说明系统变量配置成功。
第三步:配置Hadoop环境变量
Hadoop所有的配置文件都存在于安装目录下的etc/hadoop中,进入该目录,修改以下配置文件:
三个文件分别加入JAVA_HOME环境变量,如下:
export JAVA_HOME=/opt/modules/jdk1.8.0_144
第四步:配置HDFS
(1)修改配置文件core-site.xml,加入以下内容:
(2)修改配置文件hdfs-site.xml,加入以下内容:
5、配置YARN
(1)重命名mapred-site.xml.template文件为mapred-site.xml,修改mapred-site.xml文件,添加以下内容,指定任务执行框架为YARN。
6.拷贝Hadoop安装文件到其它主机
在hadoop-master节点上,将配置好的整个Hadoop安装目录拷贝到其它节点(hadoop-slave1和hadoop-slave2),命令如下:
7.格式化NameNode
启动Hadoop之前,需要先格式化NameNode。格式化NameNode可以初始化HDFS文件系统的一些目录和文件,在hadoop-master节点上执行以下命令,进行格式化操作:
8.启动Hadoop
在centos01节点上执行以下命令,启动Hadoop集群:
也可以执行start-dfs.sh和start-yarn.sh分别启动HDFS集群和YARN集群。
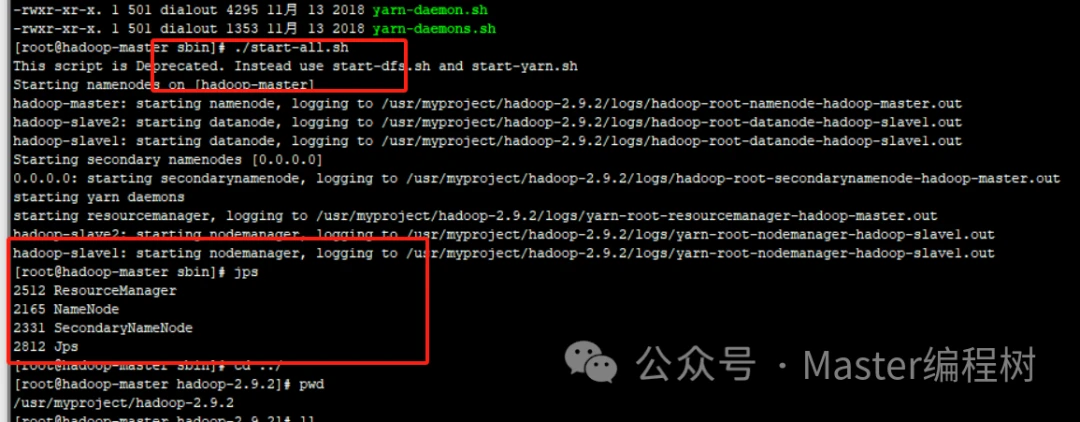
9.查看各节点启动进程
集群启动成功后,分别在各个节点上执行jps命令,查看启动的Java进程。可以看到,各节点的Java进程如下:
hadoop-master节点:

hadoop-slave2节点

在浏览器中访问:50070和18088端口,说明:有的是8088端口,具体端口是哪个,在yarn-site.xml文件中查看如下配置:
http://hadoop-master:18088/cluster
http://hadoop-master:50070
如果通过主机名无法访问,需要配置hosts文件
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/3946.html