
大家好,又见面了,我是你们的朋友全栈君。
目录
- 1. MapReduce 简介
- 1.1 起源
- 1.2 模型简介
- 1.3 MRv1体系结构
- 1.4 YARN
- 1.4.1 YARN体系结构
- 1.4.2 YARN工作流程
- 2. MapReduce 工作流程
- 3. Java Api要点
- 4. 实验过程
- 最后
- 1.1 起源
- 1.2 模型简介
- 1.3 MRv1体系结构
- 1.4 YARN
- 1.4.1 YARN体系结构
- 1.4.2 YARN工作流程
1. MapReduce 简介
1.1 起源
在函数式语言里,map表示对一个列表(List)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。
它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。
- 在MapReduce里,map处理的是原始数据,每条数据之间互相没有关系;
- 到了reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性,至少它们都在一个key下面,于是就符合函数式语言里map和reduce的基本思想了。
- “map”和“reduce”的概念和它们的主要思想,都是从函数式编程语言借用来的,还有从矢量编程语言里借来的特性。极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
1.2 模型简介
- 将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:和
- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- 采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- 设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
- 框架采用了架构,包括一个和若干个。上运行(yarn上ResourceManager),上运行(yarn上Nodemanager)
- Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
1.3 MRv1体系结构
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
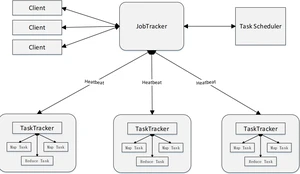
结点说明:
- Client 用户编写的程序通过提交到端,用户可通过提供的一些接口查看作业运行状态。
- JobTracker 负责资源监控和作业调度;监控所有与的健康状况,一旦发现失败,就将相应的任务转移到其他节点;会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
- TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给,同时接收发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个获取到一个后才有机会运行,而调度器的作用就是将各个上的空闲分配给使用。slot 分为和两种,分别供和使用。
- Task Task分为和两种,均由启动。
结构缺点:
- 存在单点故障
- JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
- 容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
- 资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
1.4 YARN
java编程基础操作
1.4.1 YARN体系结构
架构思想
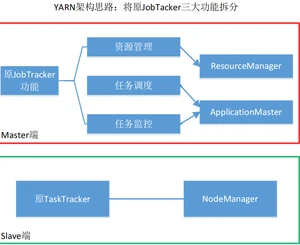
体系结构
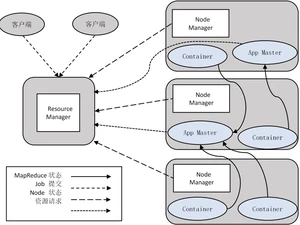
ResourceManager • 处理客户端请求 • 启动/监控ApplicationMaster • 监控NodeManager • 资源分配与调度 NodeManager • 单个节点上的资源管理 • 处理来自ResourceManger的命令 • 处理来自ApplicationMaster的命令 ApplicationMaster • 为应用程序申请资源,并分配给内部任务 • 任务调度、监控与容错
1.4.2 YARN工作流程
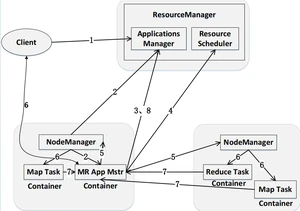
步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括程序、启动的命令、用户程序等 步骤2:中的负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个 步骤3:被创建后会首先向注册 步骤4:采用轮询的方式向申请资源 步骤5:以“容器”的形式向提出申请的分配资源 步骤6:在容器中启动任务(运行环境、脚本) 步骤7:各个任务向汇报自己的状态和进度 步骤8:应用程序运行完成后,向的应用程序管理器注销并关闭自己
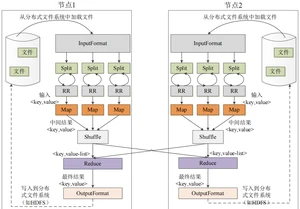
2. MapReduce 工作流程
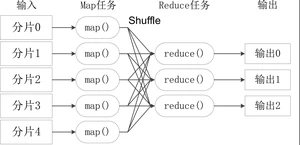
➢ 不同的Map任务之间不会进行通信 ➢ 不同的Reduce任务之间也不会发生任何信息交换 ➢ 用户不能显式地从一台机器向另一台机器发送消息 ➢ 所有的数据交换都是通过MapReduce框架自身去实现的
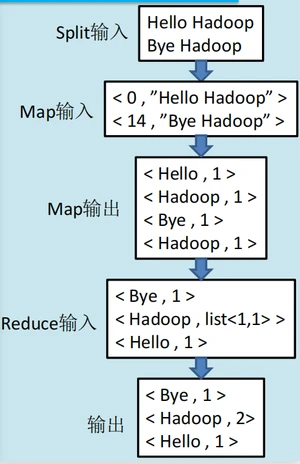
例子
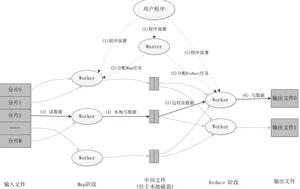
3. Java Api要点
- Writable Hadoop 自定义的序列化接口。当要在进程间传递对象或持久化对象的时候,就需要序列化对象成字节流,反之当要将接收到或从磁盘读取的字节流转换为对象,就要进行反序列化。Map 和 Reduce 的 key、value 数据格式均为 Writeable 类型,其中 key 还需实现WritableComparable 接口。Java 基本类型对应 writable 类型的封装如下:
Java primitive
Writable implementation
boolean
BooleanWritable
byte
ByteWritable
int
ShortWritable
float
FloatWritable
long
LongWritable
double
DoubleWritable
enum
EnumWritable
Map
MapWritable
(2)InputFormat 用于描述输入数据的格式。提供两个功能:
数据分片,按照某个策略将输入数据切分成若干个,以便确定任务个数以及对应的 ;,将某个解析成一个个 对。 是所有以文件作为数据源的 实现基类,小文件不会进行分片,记录读取调用子类 实现;
- 是默认处理类,处理普通文本文件,以文件中每一行作为一条记录,行起始偏移量为,每一行文本为 value;
- 针对小文件设计,可以合并小文件;
- 适合处理一行两列并以作为分隔符的数据;
- 控制每个 中的行数。
(3)OutputFormat
主要用于描述输出数据的格式。Hadoop 自带多种 OutputFormat 的实现。
- 默认的输出格式,key 和 value 中间用 tab 分隔;
- ,将 key 和 value 以 SequenceFile 格式输出;
- ,将 key 和 value 以原始二进制格式输出;
- ,将 key 和 value 写入 MapFile 中;
- ,默认情况下 Reducer 会产生一个输出,用该格式可以实现一个Reducer 多个输出。
(4)Mapper/Reducer
封装了应用程序的处理逻辑,主要由 map、reduce 方法实现。
(5)Partitioner
根据 map 输出的 key 进行分区,通过 getPartition()方法返回分区值,默认使用哈希函 数。分区的数目与一个作业的reduce任务的数目是一样的。HashPartitioner是默认的Partioner。
4. 实验过程
1、计数统计类应用 仿照 WordCount 例子,编写“TelPubXxx”类实现对拨打公共服务号码的电话信息的统计。给出的一个文本输入文件如下,第一列为电话号码、第二列为公共服务号码,中间以空格隔开。 315 110 112 110 112 114 114 MapReduce 程序执行后输出结果如下,电话号码之间用“|”连接: 110 | 112 || 114 |
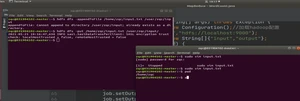
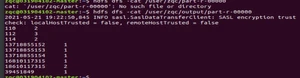
运行成功

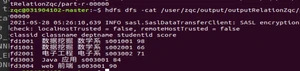
2、两表联结 Join 应用 仿照单表关联例子,编写“RelationXxx”类实现多表关联。中文文本文件转成 UTF-8 编码格式,否则会乱码。 输入 score.txt:
studentid
classid
score
s003001
fd3003
84
s003001
fd3004
90
s003002
fd2001
71
s002001
fd1001
66
s001001
fd1001
98
s001001
fd1002
60
输入 major.txt:
classid
classname
deptname
fd1001
数据挖掘
数学系
fd2001
电子工程
电子系
fd2002
电子技术
电子系
fd3001
大数据
计算机系
fd3002
网络工程
计算机系
fd3003
Java 应用
计算机系
fd3004
web 前端
计算机系
输出结果:
classid
classname
deptname
studentid
score
fd1001
数据挖掘
数学系
s001001
98
fd1001
数据挖掘
数学系
s002001
66
fd2001
电子工程
电子系
s003002
71
fd3003
Java 应用
计算机系
s003001
84
fd3004
web 前端
计算机系
s003001
90
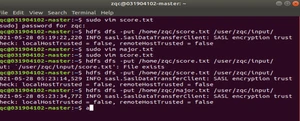
将其中需要的东西传到hdfs中去。
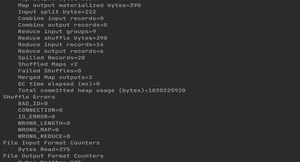
没有报错。查看结果
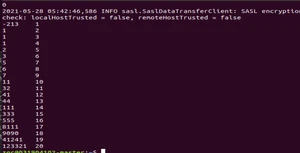
3、简单排序类应用编写 MapReduce 程序“SortXxx” 类,要求输入文件 sort1.txt、sort2.txt、sort3.txt 内容,由程序随机生成若干条数据并存储到 HDFS 上,每条数据占一行,数据可以是日期也可以是数字;输出结果为两列数据,第一列是输入文件中的原始数据,第二列是该数据的排位。

运行成功
最后
小生凡一,期待你的关注。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/3343.html