

博文链接:https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/converting-llama2-to-llama3.ipynb
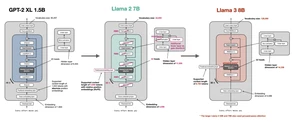
1 逐步转换 Llama 模型实现
修改旋转嵌入 实现分组查询注意力 使用定制版的 GPT-4 tokenizer
import osimport sysimport ioimport nbformatimport typesdef import_from_notebook():def import_definitions_from_notebook(fullname, names):current_dir = os.getcwd()path = os.path.join(current_dir, fullname + ".ipynb")path = os.path.normpath(path)# Load the notebookif not os.path.exists(path):raise FileNotFoundError(f"Notebook file not found at: {path}")with io.open(path, "r", encoding="utf-8") as f:nb = nbformat.read(f, as_version=4)# Create a module to store the imported functions and classesmod = types.ModuleType(fullname)sys.modules[fullname] = mod# Go through the notebook cells and only execute function or class definitionsfor cell in nb.cells:if cell.cell_type == "code":cell_code = cell.sourcefor name in names:# Check for function or class definitionsif f"def {name}" in cell_code or f"class {name}" in cell_code:exec(cell_code, mod.__dict__)return modfullname = "converting-gpt-to-llama2"names = ["precompute_rope_params", "compute_rope", "SiLU", "FeedForward", "RMSNorm", "MultiHeadAttention"]return import_definitions_from_notebook(fullname, names)
imported_module = import_from_notebook()# We need to redefine precompute_rope_params# precompute_rope_params = getattr(imported_module, "precompute_rope_params", None)compute_rope = getattr(imported_module, "compute_rope", None)SiLU = getattr(imported_module, "SiLU", None)FeedForward = getattr(imported_module, "FeedForward", None)RMSNorm = getattr(imported_module, "RMSNorm", None)# MultiHeadAttention only for comparison purposesMultiHeadAttention = getattr(imported_module, "MultiHeadAttention", None)
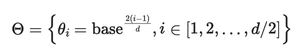
import torchdef precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):assert head_dim % 2 == 0, "Embedding dimension must be even"# Compute the inverse frequenciesinv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))################################ NEW ################################################ Frequency adjustmentsif freq_config is not None:low_freq_wavelen = freq_config["original_context_length"] / freq_config["low_freq_factor"]high_freq_wavelen = freq_config["original_context_length"] / freq_config["high_freq_factor"]wavelen = 2 * torch.pi / inv_freqinv_freq_llama = torch.where(wavelen > low_freq_wavelen, inv_freq / freq_config["factor"], inv_freq)smooth_factor = (freq_config["original_context_length"] / wavelen - freq_config["low_freq_factor"]) / (freq_config["high_freq_factor"] - freq_config["low_freq_factor"])smoothed_inv_freq = ((1 - smooth_factor) * (inv_freq / freq_config["factor"]) + smooth_factor * inv_freq)is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)inv_freq = inv_freq_llama##################################################################################### Generate position indicespositions = torch.arange(context_length)# Compute the anglesangles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)# Expand angles to match the head_dimangles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)# Precompute sine and cosinecos = torch.cos(angles)sin = torch.sin(angles)return cos, sin
# Instantiate RoPE parametersllama_2_context_len = 4096llama_3_context_len = 8192llama_2_theta_base = 10_000llama_3_theta_base = 50_000
# Settingsbatch_size = 2num_heads = 4head_dim = 16# Instantiate RoPE parameterscos, sin = precompute_rope_params(head_dim=head_dim,theta_base=llama_3_theta_base,context_length=llama_3_context_len)# Dummy query and key tensorstorch.manual_seed(123)queries = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)keys = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)# Apply rotary position embeddingsqueries_rot = compute_rope(queries, cos, sin)keys_rot = compute_rope(keys, cos, sin)
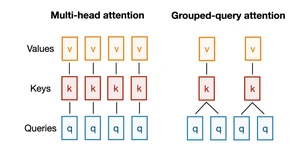
import torch.nn as nnclass GroupedQueryAttention(nn.Module):def __init__(self, d_in, d_out, context_length, num_heads,num_kv_groups, # NEWrope_base=10_000, # NEWrope_config=None, # NEWdtype=None):super().__init__()assert d_out % num_heads == 0, "d_out must be divisible by num_heads"assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"self.d_out = d_outself.num_heads = num_headsself.head_dim = d_out // num_heads############################# NEW ############################## self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)# self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)self.num_kv_groups = num_kv_groupsself.group_size = num_heads // num_kv_groups################################################################self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))cos, sin = precompute_rope_params(head_dim=self.head_dim,theta_base=rope_base, # NEWfreq_config=rope_config, # NEWcontext_length=8192)self.register_buffer("cos", cos)self.register_buffer("sin", sin)def forward(self, x):b, num_tokens, d_in = x.shapequeries = self.W_query(x) # Shape: (b, num_tokens, d_out)keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)# Reshape queries, keys, and valuesqueries = queries.view(b, num_tokens, self.num_heads, self.head_dim)##################### NEW ###################### keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)# values = values.view(b, num_tokens, self.num_heads, self.head_dim)keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)################################################# Transpose keys, values, and querieskeys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)# Apply RoPEkeys = compute_rope(keys, self.cos, self.sin)queries = compute_rope(queries, self.cos, self.sin)##################### NEW ###################### Expand keys and values to match the number of heads# Shape: (b, num_heads, num_tokens, head_dim)keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)# For example, before repeat_interleave along dim=1 (query groups):# [K1, K2]# After repeat_interleave (each query group is repeated group_size times):# [K1, K1, K2, K2]# If we used regular repeat instead of repeat_interleave, we'd get:# [K1, K2, K1, K2]################################################# Compute scaled dot-product attention (aka self-attention) with a causal mask# Shape: (b, num_heads, num_tokens, num_tokens)attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head# Original mask truncated to the number of tokens and converted to booleanmask_bool = self.mask.bool()[:num_tokens, :num_tokens]# Use the mask to fill attention scoresattn_scores.masked_fill_(mask_bool, -torch.inf)attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)assert keys.shape[-1] == self.head_dim# Shape: (b, num_tokens, num_heads, head_dim)context_vec = (attn_weights @ values).transpose(1, 2)# Combine heads, where self.d_out = self.num_heads * self.head_dimcontext_vec = context_vec.reshape(b, num_tokens, self.d_out)context_vec = self.out_proj(context_vec) # optional projectionreturn context_vec
# Settingsbatch_size = 1context_len = 3000max_context_len = 8192embed_dim = 4096num_heads = 32example_batch = torch.randn((batch_size, context_len, embed_dim))mha = MultiHeadAttention(d_in=embed_dim,d_out=embed_dim,context_length=max_context_len,num_heads=num_heads)mha(example_batch)print("W_key:", mha.W_key.weight.shape)print("W_value:", mha.W_value.weight.shape)print("W_query:", mha.W_query.weight.shape)
W_key: torch.Size([4096, 4096])W_value: torch.Size([4096, 4096])W_query: torch.Size([4096, 4096])
gqa = GroupedQueryAttention(d_in=embed_dim,d_out=embed_dim,context_length=max_context_len,num_heads=num_heads,num_kv_groups=8,rope_base=llama_3_theta_base)gqa(example_batch)print("W_key:", gqa.W_key.weight.shape)print("W_value:", gqa.W_value.weight.shape)print("W_query:", gqa.W_query.weight.shape)
W_key: torch.Size([1024, 4096])W_value: torch.Size([1024, 4096])W_query: torch.Size([4096, 4096])
print("Total number of parameters:")mha_total_params = sum(p.numel() for p in mha.parameters())print(f"MHA: {mha_total_params:,}")gqa_total_params = sum(p.numel() for p in gqa.parameters())print(f"GQA: {gqa_total_params:,}")
Total number of parameters:MHA: 67,108,864GQA: 41,943,040
# Free up memory:del mhadel gqa
class TransformerBlock(nn.Module):def __init__(self, cfg):super().__init__()self.att = GroupedQueryAttention( # MultiHeadAttention(d_in=cfg["emb_dim"],d_out=cfg["emb_dim"],context_length=cfg["context_length"],num_heads=cfg["n_heads"],num_kv_groups=cfg["n_kv_groups"], # NEWrope_base=cfg["rope_base"], # NEWrope_config=cfg["rope_freq"], # NEWdtype=cfg["dtype"])self.ff = FeedForward(cfg)self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-5)self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-5)def forward(self, x):# Shortcut connection for attention blockshortcut = xx = self.norm1(x)x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]x = x + shortcut # Add the original input back# Shortcut connection for feed-forward blockshortcut = xx = self.norm2(x)x = self.ff(x.to(torch.bfloat16))x = x + shortcut # Add the original input backreturn x
# class Llama2Model(nn.Module):class Llama3Model(nn.Module):def __init__(self, cfg):super().__init__()self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])self.trf_blocks = nn.Sequential(*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])self.final_norm = RMSNorm(cfg["emb_dim"], eps=1e-5)self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])def forward(self, in_idx):batch_size, seq_len = in_idx.shapetok_embeds = self.tok_emb(in_idx)x = tok_embedsx = self.trf_blocks(x)x = self.final_norm(x)logits = self.out_head(x.to(torch.bfloat16))return logits
2 初始化模型
LLAMA2_CONFIG_7B = {"vocab_size": 32_000, # Vocabulary size"context_length": 4096, # Context length"emb_dim": 4096, # Embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 32, # Number of layers"hidden_dim": 11_008, # Size of the intermediate dimension in FeedForward"dtype": torch.bfloat16 # Lower-precision dtype to save memory}
LLAMA3_CONFIG_8B = {"vocab_size": 128_256, # NEW: Larger vocabulary size"context_length": 8192, # NEW: Larger context length"emb_dim": 4096, # Embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 32, # Number of layers"hidden_dim": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward"n_kv_groups": 8, # NEW: Key-Value groups for grouped-query attention"rope_base": 50_000, # NEW: The base in RoPE's "theta" was increased to 50_000"rope_freq": None, # NEW: Additional configuration for adjusting the RoPE frequencies"dtype": torch.bfloat16 # Lower-precision dtype to save memory}
model = Llama3Model(LLAMA3_CONFIG_8B)total_params = sum(p.numel() for p in model.parameters())print(f"Total number of parameters: {total_params:,}")
Total number of parameters: 8,030,261,248def model_memory_size(model, input_dtype=torch.float32):total_params = 0total_grads = 0for param in model.parameters():# Calculate total number of elements per parameterparam_size = param.numel()total_params += param_size# Check if gradients are stored for this parameterif param.requires_grad:total_grads += param_size# Calculate buffer size (non-parameters that require memory)total_buffers = sum(buf.numel() for buf in model.buffers())# Size in bytes = (Number of elements) * (Size of each element in bytes)# We assume parameters and gradients are stored in the same type as input dtypeelement_size = torch.tensor(0, dtype=input_dtype).element_size()total_memory_bytes = (total_params + total_grads + total_buffers) * element_size# Convert bytes to gigabytestotal_memory_gb = total_memory_bytes / (1024**3)return total_memory_gbprint(f"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB")print(f"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB")float32 (PyTorch default): 68.08 GBbfloat16: 34.04 GB
if torch.cuda.is_available():device = torch.device("cuda")elif torch.backends.mps.is_available():device = torch.device("mps")else:device = torch.device("cpu")model.to(device);
3 加载 tokenizer
import osfrom pathlib import Pathimport tiktokenfrom tiktoken.load import load_tiktoken_bpeclass Tokenizer:def __init__(self, model_path):assert os.path.isfile(model_path), f"Model file {model_path} not found"mergeable_ranks = load_tiktoken_bpe(model_path)num_base_tokens = len(mergeable_ranks)self.special_tokens = {"<|begin_of_text|>": 128000,"<|end_of_text|>": 128001,"<|start_header_id|>": 128006,"<|end_header_id|>": 128007,"<|eot_id|>": 128009,}self.special_tokens.update({f"<|reserved_{i}|>": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()})self.model = tiktoken.Encoding(name=Path(model_path).name,pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",mergeable_ranks=mergeable_ranks,special_tokens=self.special_tokens)def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):if bos:tokens = [self.special_tokens["<|begin_of_text|>"]]else:tokens = []tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)if eos:tokens.append(self.special_tokens["<|end_of_text|>"])return tokensdef decode(self, tokens):return self.model.decode(tokens)
from huggingface_hub import loginimport jsonwith open("config.json", "r") as config_file:config = json.load(config_file)access_token = config["HF_ACCESS_TOKEN"]login(token=access_token)
The token has not been saved to the git credentials helper. Pass `add_to_git_credential=True` in this function directly or `--add-to-git-credential` if using via `huggingface-cli` if you want to set the git credential as well.Token is valid (permission: read).Your token has been saved to /root/.cache/huggingface/tokenLogin successful
from huggingface_hub import hf_hub_downloadtokenizer_file_path = hf_hub_download(repo_id="meta-llama/Meta-Llama-3-8B",filename="original/tokenizer.model",local_dir="llama3-files")
# pip install blobfiletokenizer = Tokenizer(tokenizer_file_path)from previous_chapters import generate, text_to_token_ids, token_ids_to_texttorch.manual_seed(123)token_ids = generate(model=model,idx=text_to_token_ids("Every effort", tokenizer).to(device),max_new_tokens=30,context_size=LLAMA3_CONFIG_8B["context_length"],top_k=1,temperature=0.)print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:Every effort_dead aeros Ingredients başında.extension clangmissions.esp 사진 Ek Pars til DoctorsDaoеньostivan normal Ekized � Ekized � Ek rdr tık%,orgen>',
4 加载预训练权重
from safetensors.torch import load_filecombined_weights = {}for i in range(1, 5):weights_file = hf_hub_download(repo_id="meta-llama/Meta-Llama-3-8B",filename=f"model-0000{i}-of-00004.safetensors",local_dir="llama3-files")current_weights = load_file(weights_file)combined_weights.update(current_weights)model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00<?, ?B/s]model-00002-of-00004.safetensors: 0%| | 0.00/5.00G [00:00<?, ?B/s]model-00003-of-00004.safetensors: 0%| | 0.00/4.92G [00:00<?, ?B/s]model-00004-of-00004.safetensors: 0%| | 0.00/1.17G [00:00<?, ?B/s]
list(combined_weights.keys())[:15]['model.embed_tokens.weight','model.layers.0.input_layernorm.weight','model.layers.0.mlp.down_proj.weight','model.layers.0.mlp.gate_proj.weight','model.layers.0.mlp.up_proj.weight','model.layers.0.post_attention_layernorm.weight','model.layers.0.self_attn.k_proj.weight','model.layers.0.self_attn.o_proj.weight','model.layers.0.self_attn.q_proj.weight','model.layers.0.self_attn.v_proj.weight','model.layers.1.input_layernorm.weight','model.layers.1.mlp.down_proj.weight','model.layers.1.mlp.gate_proj.weight','model.layers.1.mlp.up_proj.weight','model.layers.1.post_attention_layernorm.weight']
def assign(left, right, tensor_name="unknown"):if left.shape != right.shape:raise ValueError(f"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}")if isinstance(right, torch.Tensor):return torch.nn.Parameter(right.clone().detach())else:return torch.nn.Parameter(torch.tensor(right))def load_weights_into_llama(model, param_config, params):model.tok_emb.weight = assign(model.tok_emb.weight, params["model.embed_tokens.weight"], "model.embed_tokens.weight")for l in range(param_config["n_layers"]):# Load attention weightsmodel.trf_blocks[l].att.W_query.weight = assign(model.trf_blocks[l].att.W_query.weight,params[f"model.layers.{l}.self_attn.q_proj.weight"],f"model.layers.{l}.self_attn.q_proj.weight")model.trf_blocks[l].att.W_key.weight = assign(model.trf_blocks[l].att.W_key.weight,params[f"model.layers.{l}.self_attn.k_proj.weight"],f"model.layers.{l}.self_attn.k_proj.weight")model.trf_blocks[l].att.W_value.weight = assign(model.trf_blocks[l].att.W_value.weight,params[f"model.layers.{l}.self_attn.v_proj.weight"],f"model.layers.{l}.self_attn.v_proj.weight")model.trf_blocks[l].att.out_proj.weight = assign(model.trf_blocks[l].att.out_proj.weight,params[f"model.layers.{l}.self_attn.o_proj.weight"],f"model.layers.{l}.self_attn.o_proj.weight")model.trf_blocks[l].norm1.weight = assign(model.trf_blocks[l].norm1.weight,params[f"model.layers.{l}.input_layernorm.weight"],f"model.layers.{l}.input_layernorm.weight")# Load FeedForward weightsmodel.trf_blocks[l].ff.fc1.weight = assign(model.trf_blocks[l].ff.fc1.weight,params[f"model.layers.{l}.mlp.gate_proj.weight"],f"model.layers.{l}.mlp.gate_proj.weight")model.trf_blocks[l].ff.fc2.weight = assign(model.trf_blocks[l].ff.fc2.weight,params[f"model.layers.{l}.mlp.up_proj.weight"],f"model.layers.{l}.mlp.up_proj.weight")model.trf_blocks[l].ff.fc3.weight = assign(model.trf_blocks[l].ff.fc3.weight,params[f"model.layers.{l}.mlp.down_proj.weight"],f"model.layers.{l}.mlp.down_proj.weight")model.trf_blocks[l].norm2.weight = assign(model.trf_blocks[l].norm2.weight,params[f"model.layers.{l}.post_attention_layernorm.weight"],f"model.layers.{l}.post_attention_layernorm.weight")# Load output layer weightsmodel.final_norm.weight = assign(model.final_norm.weight, params["model.norm.weight"], "model.norm.weight")if "lm_head.weight" in params.keys():model.out_head.weight = assign(model.out_head.weight, params["lm_head.weight"], "lm_head.weight")else:model.out_head.weight = assign(model.out_head.weight, params["model.embed_tokens.weight"], "model.embed_tokens.weight")print("Model uses weight tying.")load_weights_into_llama(model, LLAMA3_CONFIG_8B, combined_weights)model.to(device);del combined_weights # free up memory
torch.manual_seed(123)token_ids = generate(model=model,idx=text_to_token_ids("Every effort", tokenizer).to(device),max_new_tokens=25,context_size=LLAMA3_CONFIG_8B["context_length"],top_k=1,temperature=0.)print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:Every effort has been made to trace copyright holders and to obtain their permission for the use of copyright material. The publisher apologizes for any
5 使用指令微调模型
# to free up memoryimport gcdel modelgc.collect() # Run Python garbage collectorif torch.cuda.is_available():torch.cuda.empty_cache()
combined_weights = {}for i in range(1, 5):weights_file = hf_hub_download(repo_id="meta-llama/Meta-Llama-3-8B-Instruct",filename=f"model-0000{i}-of-00004.safetensors",local_dir="llama3-files")current_weights = load_file(weights_file)combined_weights.update(current_weights)model = Llama3Model(LLAMA3_CONFIG_8B)load_weights_into_llama(model, LLAMA3_CONFIG_8B, combined_weights)model.to(device)del combined_weights # free up memory
model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00<?, ?B/s] model-00002-of-00004.safetensors: 0%| | 0.00/5.00G [00:00<?, ?B/s]model-00003-of-00004.safetensors: 0%| | 0.00/4.92G [00:00<?, ?B/s]model-00004-of-00004.safetensors: 0%| | 0.00/1.17G [00:00<?, ?B/s]class ChatFormat:def __init__(self, tokenizer):self.tokenizer = tokenizerdef encode_header(self, message):tokens = []tokens.append(self.tokenizer.special_tokens["<|start_header_id|>"])tokens.extend(self.tokenizer.encode(message["role"], bos=False, eos=False))tokens.append(self.tokenizer.special_tokens["<|end_header_id|>"])tokens.extend(self.tokenizer.encode("\n\n", bos=False, eos=False))return tokensdef encode(self, text):message = {"role": "user","content": text}tokens = self.encode_header(message)tokens.extend(self.tokenizer.encode(message["content"].strip(), bos=False, eos=False))tokens.append(self.tokenizer.special_tokens["<|eot_id|>"])return tokensdef decode(self, token_ids):return self.tokenizer.decode(token_ids)chat_tokenizer = ChatFormat(tokenizer)
token_ids = chat_tokenizer.encode("Hello World!")print(token_ids)
[128006, 882, 128007, 271, 9906, 4435, 0, 128009]tokenizer.decode(token_ids)'<|start_header_id|>user<|end_header_id|>\n\nHello World!<|eot_id|>'import retorch.manual_seed(123)token_ids = generate(model=model,idx=text_to_token_ids("What do llamas eat?", chat_tokenizer).to(device),max_new_tokens=150,context_size=LLAMA3_CONFIG_8B["context_length"],top_k=1,temperature=0.)output_text = token_ids_to_text(token_ids, tokenizer)def clean_text(text, header_end="assistant<|end_header_id|>\n\n"):# Find the index of the first occurrence of "<|end_header_id|>"index = text.find(header_end)if index != -1:# Return the substring starting after "<|end_header_id|>"return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespaceelse:# If the token is not found, return the original textreturn textprint("Output text:\n", clean_text(output_text))
Output text:Llamas are herbivores, which means they primarily eat plants and plant-based foods. Here are some of the things llamas like to eat:1. Grass: Llamas love to graze on grass, especially in the spring and summer months.2. Hay: Hay is a staple in a llama's diet. They like to eat timothy hay, alfalfa hay, and other types of hay.3. Grains: Llamas may also be fed grains like oats, barley, and corn. However, grains should not make up more than 10% of a llama's diet.4. Fruits and vegetables: Llamas may enjoy fruits and vegetables as treats, such as apples,
Llama 3.1 8B
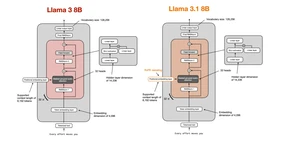
LLAMA3_CONFIG_8B = {"vocab_size": 128_256, # Vocabulary size"context_length": 8192, # Context length"emb_dim": 4096, # Embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 32, # Number of layers"hidden_dim": 14_336, # Size of the intermediate dimension in FeedForward"n_kv_groups": 8, # Key-Value groups for grouped-query attention"rope_base": 50_000, # The base in RoPE's "theta""rope_freq": None, # Additional configuration for adjusting the RoPE frequencies"dtype": torch.bfloat16 # Lower-precision dtype to save memory}LLAMA31_CONFIG_8B = {"vocab_size": 128_256, # Vocabulary size"context_length": 8192, # Context length"emb_dim": 4096, # Embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 32, # Number of layers"hidden_dim": 14_336, # Size of the intermediate dimension in FeedForward"n_kv_groups": 8, # Key-Value groups for grouped-query attention"rope_base": 50_000, # The base in RoPE's "theta""dtype": torch.bfloat16, # Lower-precision dtype to save memory"rope_freq": { # NEW: RoPE frequency scaling"factor": 8.0,"low_freq_factor": 1.0,"high_freq_factor": 4.0,"original_context_length": 8192,}}
# free up memorydel modelgc.collect() # Run Python garbage collectorif java基础 传智播客毕向东 torch.cuda.is_available():torch.cuda.empty_cache()
tokenizer_file_path = hf_hub_download(repo_id="meta-llama/Llama-3.1-8B",filename="original/tokenizer.model",local_dir="llama3-files")tokenizer = Tokenizer(tokenizer_file_path)model = Llama3Model(LLAMA31_CONFIG_8B)total_params = sum(p.numel() for p in model.parameters())print(f"Total number of parameters: {total_params:,}")Total number of parameters: 8,030,261,248combined_weights = {}for i in range(1, 5):weights_file = hf_hub_download(repo_id="meta-llama/Llama-3.1-8B",filename=f"model-0000{i}-of-00004.safetensors",local_dir="llama3-files")current_weights = load_file(weights_file)combined_weights.update(current_weights)load_weights_into_llama(model, LLAMA31_CONFIG_8B, combined_weights)model.to(device);model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00<?, ?B/s]model-00002-of-00004.safetensors: 0%| | 0.00/5.00G [00:00<?, ?B/s]model-00003-of-00004.safetensors: 0%| | 0.00/4.92G [00:00<?, ?B/s]model-00004-of-00004.safetensors: 0%| | 0.00/1.17G [00:00<?, ?B/s]torch.manual_seed(123)token_ids = generate(model=model,idx=text_to_token_ids("Every effort", tokenizer).to(device),max_new_tokens=25,context_size=LLAMA31_CONFIG_8B["context_length"],top_k=1,temperature=0.)print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:Every effort has been made to trace copyright holders and to obtain their permission for the use of copyright material. The publisher apologizes for any
Llama 3.2 1B
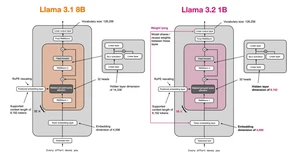
LLAMA31_CONFIG_8B = {"vocab_size": 128_256, # Vocabulary size"context_length": 8192, # Context length"emb_dim": 4096, # Embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 32, # Number of layers"hidden_dim": 14_336, # Size of the intermediate dimension in FeedForward"n_kv_groups": 8, # Key-Value groups for grouped-query attention"rope_base": 50_000, # The base in RoPE's "theta""dtype": torch.bfloat16, # Lower-precision dtype to save memory"rope_freq": { # RoPE frequency scaling"factor": 8.0,"low_freq_factor": 1.0,"high_freq_factor": 4.0,"original_context_length": 8192,}}LLAMA32_CONFIG_1B = {"vocab_size": 128_256, # Vocabulary size"context_length": 8192, # Context length"emb_dim": 2048, # NEW: Half the embedding dimension"n_heads": 32, # Number of attention heads"n_layers": 16, # NEW: Half the number of layers"hidden_dim": 8192, # NEW: Almopst half the size of the intermediate dimension in FeedForward"n_kv_groups": 8, # Key-Value groups for grouped-query attention"rope_base": 50_000, # The base in RoPE's "theta""dtype": torch.bfloat16, # Lower-precision dtype to save memory"rope_freq": { # RoPE frequency scaling"factor": 32.0, # NEW: Adjustment of the rescaling factor"low_freq_factor": 1.0,"high_freq_factor": 4.0,"original_context_length": 8192,}}
# free up memorydel modelgc.collect() # Run Python garbage collectorif torch.cuda.is_available():torch.cuda.empty_cache()
tokenizer_file_path = hf_hub_download(repo_id="meta-llama/Llama-3.2-1B",filename="original/tokenizer.model",local_dir="llama32-files")tokenizer = Tokenizer(tokenizer_file_path)
model = Llama3Model(LLAMA32_CONFIG_1B)total_params = sum(p.numel() for p in model.parameters())print(f"Total number of parameters: {total_params:,}")# Account for weight tyingtotal_params_normalized = total_params - model.tok_emb.weight.numel()print(f"\nTotal number of unique parameters: {total_params_normalized:,}")
Total number of parameters: 1,498,482,688Total number of unique parameters: 1,235,814,400
weights_file = hf_hub_download(repo_id="meta-llama/Llama-3.2-1B",filename=f"model.safetensors",local_dir="llama32-files")current_weights = load_file(weights_file)load_weights_into_llama(model, LLAMA32_CONFIG_1B, current_weights)model.to(device);
Model uses weight tying.print("Weight tying:", torch.equal(model.tok_emb.weight, model.out_head.weight))Weight tying: Truetorch.manual_seed(123)token_ids = generate(model=model,idx=text_to_token_ids("Every effort", tokenizer).to(device),max_new_tokens=25,context_size=LLAMA32_CONFIG_1B["context_length"],top_k=1,temperature=0.)print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:Every effort is made to ensure that the information on this website is accurate. However, we cannot guarantee that the information is accurate, complete

扫描二维码添加小助手微信
关于我们

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/26047.html