
一、Java基础信息
程序(application):一组有序的指令集合
指令:就是命令的意思
java的组成:javase/j2se(java标准版),javaee/j2ee(java企业版)(13几种技术)
java的应用:internet程序(b/s)和桌面应用程序(c/s) browser
什么是java:是一种面向对象的高级编程语言
安装jdk ,下载,8
配置jdk:选中计算机右键属性->高级系统设置->环境变量->系统变量的path里配置jdk路径
验证jdk是否配置成功 开始->cmd->java -version
记事本开发程序的步骤
①编写:编写源文件Test.java 编译javac Test.java
②编译:字节码Test.class 运行java Test
③运行:运行结果
1.1java的基本结构信息
public class Test{
public static void main(String[] args){
System.out.println("你好");
}
}
public 公共的class 类static 静态void 无返回值main 主要的String 字符串System 系统out 输出print 打印
注意四点:
①类名的首字母要大写,要保证类名与文件名一样
②所有的括号要成对出现,遇到大括号的开始要缩进,大括号的结束要与其对应大括号的开始最前端对齐
java执行基础知识
③所有标点符号都是英文的
④每行只能放一句代码,每句以分号结束
打印:
System.out.print(); 只打印
System.out.println(); 打印+换行
转义:反斜杠必须双引号
制表位
换行
注释:
单行注释 ://注释内容 添加和取消:ctrl+/
段落注释:/*注释内容*/ 添加:ctrl+shift+/ 取消:ctrl+shift+/
1.2数据类型、变量、运算符
数据类型、变量、运算符、类型转化 Scanner
标识符:凡是人为可以起名字的地方
java关键字:java自用的单词代表某种意义,所有 关键字都是小写的
1.2.1数据类型:
①整型 int:不带小数点的 数字,例如 5,15,20 ,-1都是整型数据
byte 1、short 2、int 4、long 8
②浮点型 double:带小数点的 数字:例如5.0,10.2,100.1 都是浮点型数据
③字符串型 String:双引号引起来的 0,1或多个任意字符 例如 "","我","☆abc@!我" 都是字符串数据
④字符型 char:单引号引起来的 单个任意字符, 例如:'a','1','@','我','☆'
⑤布尔型 boolean:描述现实中的两种的东西,他的值只有两个 true,false
1.2.2变量:
就是模拟现实中的容器,用来存取数据
变量的三要素:
变量名,变量类型,变量值
定义变量:int a = 10;
变量的三步走:
①声明变量:数据类型 变量名; 例如 int a;String s;char c;boolean b;double d; 造容器的意思
②赋值:变量名=数据; 例如: a =5;s="你好"; 装东西的意思
③取值(使用):System.out.println(变量名);例如 int b; b = a 取东西的意思
变量的命名规则(标识符):
①变量名只能有四部分组成(字母,数字,下划线_,美元符号$)任意组成,但数字不能开头
②不能与java关键字重名
③见名知意(语义化,在实际开发中有助于维护)
④驼峰标志(小驼峰:第一个单词小写,剩下接着的首字母大写)
注:声明两个同名变量导致编译错误
1.2.3运算符:
①赋值运算符 =
- 后面的给前面,后面的复制一份给前面
- 前面如果有值,扔掉,接受后面的值
②算术运算符:整型跟整型运算最终结果是整型,取整数部分
+ 加 - 减 * 乘 / 除
% 求余,求模,取余,取模
③关系运算符:最终结果是boolean
> < >= <= == !=
④逻辑运算符:两个只能放boolean类型
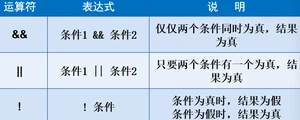
⑤一元运算符:两边只能跟数字变量
++ --
在前:先自+/-,再赋值计算
在后:先赋值计算,再自+/-
(注意:每次自增自减1。一元运算符在变量之后,先做别的运算,再将自身值+1,运算符在变量之前,先自身值+1,再其他运算)
三元运算符 这里不提
![]()
小括号()最高
赋值= 最低
1.2.4类型转换 :

注意点:①任何数据类型跟字符串相加往字符串去转
3.小转大为自动转换(大包含小的类型)
4.大转小为强制转换(大的类型比小大类型存在多余的部分)
②如果一个操作数为double型,则整个表达式可提升为double型
③默认是自动转换
强制转换:数值类型(整型和浮点型)互相兼容
(类型名)表达式
int a = (int)5.5;
目标类型<源类型(大转小)强转
自动转换:
double d = 5;//前有隐形的int
目标类型>源类型(小转大)自转
1.2.5Scanner(扫描仪):
代码阻塞,获取用户的输入,和输出打印语句长连用
Scanner in = new Scanner(System.in);
in.next();//不能得到带有空格的字符串
in.nextInt();// 接收整数
in.nextDouble();//接受多浮点型(双精度)
in.nextBoolean();//接受布尔型
in.nextFloat();// 接收小数(单精度)
in.nextLine();//可以获得空白
in.next();//不能得到带有空格的字符串
①random随机数
Random r = new Random();
r.nextInt(3);
Math.random() 范围 :[0.0,1.0)
(max+1-min)*Math.random()+min
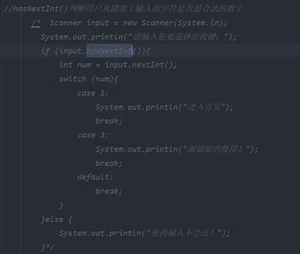
②hasNextInt()

处理系统异常

2.循环
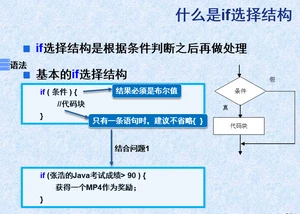
2.1单支结构:if
2.2双支结构if-else
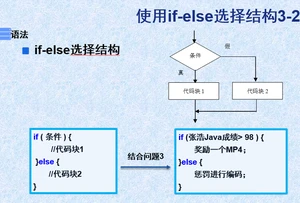
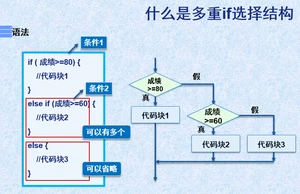
多支:if-else if.....-else(范围小的写上面)
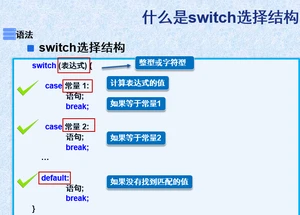
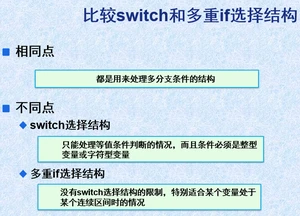
2.3switch选择结构
switch选择结构适用于条件判断是等值判断的情况



![]()


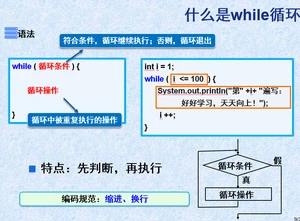
2.4while循环

③.equals()
方法用于判断 Number 对象与方法的参数进是否相等。
④为什么需要程序调试?
在编写程序过程中有时也出现错误,但不好发现和定位错误,
通过代码阅读或者加输出语句查找程序错误
当程序结构越来越复杂时,需要专门的技术来发现和定位错误,就是“程序调试”
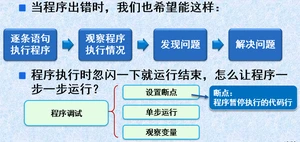
1、程序调试的目的?
找出缺陷原因,修正缺陷
2、程序调试的主要方法?
设置断点、单步执行、观察变量
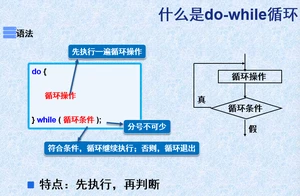
2.5do.....while


2.6for循环
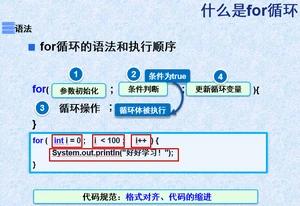
⑤break:改变程序控制流
用于do-while、while、for中时,可跳出循环而执行循环后面的语句
⑥continue:只能用在循环里
跳过循环体中剩余的语句而执行下一次循环
break语句终止某个循环,程序跳转到循环块外的下一条语句
continue跳出本次循环,进入下一次循环

二、进阶版Java
1.面向对象oop(object orientend programming)
(面试题)1.0对象创建流程:p对象(p引用指向的这个对象)
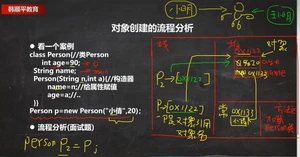
流程步骤:堆里放着的是对象
栈里的p就是对象的引用/对象名(好比一个人有多个名字,栈---代名词)
Person p = new Person("小倩",20);:
第一步:先在方法区加载Person类
第二步:new: 先在 堆 里面开辟带有地址的一个空间
第三步:先对属性默认初始化 看Person类里有几个属性(age 0,name null)
然后显示的初始化,Person类里有对age赋值(age 90,name null)引用数据类型不能直接存放在栈中,基本数据类型可以。
第四步:Person("小倩",20) 对构造器(对 对象的初始化,而不是创建对象)进行处理
①把构造器里的形参与实参对应,把小倩给n,最后给name属性。
此时,在方法区的常量池里开辟一个空间有一个地址,小倩就放在这里。
与此同时堆里面对应的 属性地址 里的name属性 的属性值 就有一个对应的地址,此时这个地址就指向它。
就把name的null 换成小倩了。
同比:
把20传给a,a赋给age,此时age就换成了20。
第五步:new Person("小倩",20)加载完成后
在栈里开辟空间时 空间里放着p
把堆里的地址返回给p,p就是对象的引用
p就指向了堆里的对应的空间
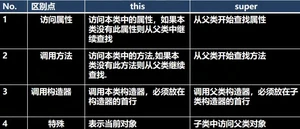
⑦this关键字
指的是当前对象
this.类成员(成员变量和成员方法) 可以用在所有方法内
this(参数):他的意思调用本类的构造器,只能用在构造器里的第一行
如果本类没有指的是上一级,依次类推,知道object类。
⑧static关键字
静态的不能访问非静态的,非静态的可以调用静态的
同一时刻,该类的所有对象中该变量值都相同
static静态的 只能修饰类成员,一但修饰了类成员,类成员属于类,不属于对象
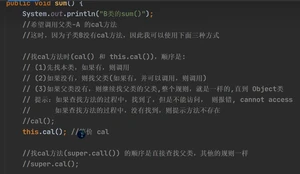
⑨super()

super 给编程带来的便利/细节 :

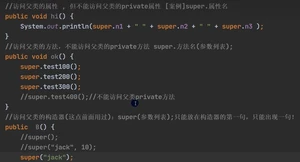
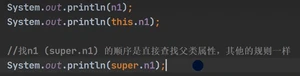
查找属性和下面的的查找方法一样的规则:
super 和 this 的比较 :
⑩final关键字
修饰类:类不能被继承
修饰方法:方法不能被重写
修饰变量:变量不能被重新赋值
具有安全机制。
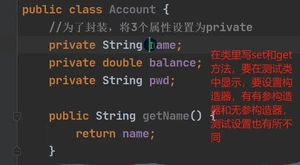
1.1封装encaspulation
字面意思:定义私有的属性,用公共的方法去访问
真正意思:隐藏细节,对外提供接口

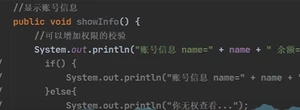
1.2构造器construtor
构造器是对 对象的初始化 而不是创建对象
快捷键:fn+alt+insert
方法名和类名一样,没有返回类型 public 类名(){}
特点:
①你写不写都有一个默认构造器,一但添加了带参的构造器,默认的消失
②先执行父类的构造器,再执行子类的构造器
作用:起到初始化的作用,创建对象调用
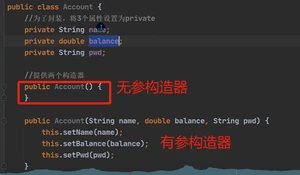
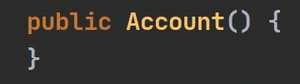
无参构造
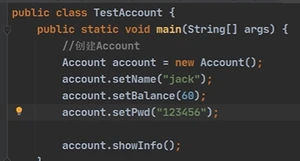
有参构造
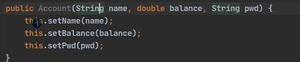
this可有可无,默认就是当前的

1.3继承
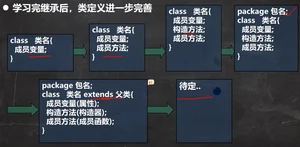
B继承A,A拥有B的所有(除私有和构造器)
继承条件:满足B是A的说法,B继承A。 不能滥用继承,子类和父类之间必须满足 is-a 的逻辑关系
特点:
①单根性:一个类只能有一个父类。 子类最多只能继承一个父类(指直接继承),即 java 中是单继承机制。 思考:如何让 A 类继承 B 类和 C 类? 【A 继承 B, B 继承 C】
②传递性:子类拥有 父类的非私有的类成员(成员变量和成员方法),私有的类成员可以通过父类提供的公共的方法去访问。
③默认情况下都会先调用父类的构造器,一直到所调用的当前的构造器。子类必须调用父类的构造器, 完成父类的初始 。( 父类构造器的调用不限于直接父类!将一直往上追溯直到 Object 类(顶级父类) 。 java 所有类都是 Object 类的子类, Object 是所有类的基类)
④ 当创建子类对象时,不管使用子类的哪个构造器,默认情况下总会去调用父类的无参构造器。【如果父类无参构造器被有参构造器覆盖了,则必须在子类的构造器中用 super(属性值...); 去指定使用父类的哪个构造器,完成对父类的初始化工作,否则,不会通过 。】
⑤如果希望指定去调用父类的某个构造器,则显式的调用一下 : super(对应的实参);
⑥ super() 和 this() 都只能放在构造器第一行,因此这两个方法不能共存在一个构造器
语法:public class B extends A{}
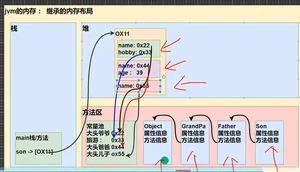
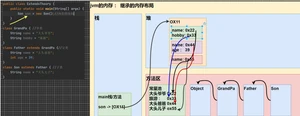
子类创建的内存布局:
栈:main方法,开辟Son空间
堆:引用数据类型的属性、基本数据类型的属性和属性值。地址给栈中的main方法。
方法区:
常量池:堆里面 引用数据类型的属性值。地址给堆中的属性。
类之间的继承关系
访问修饰符
public都有访问权限(本类、不同类同包、不同包继承、不同包不继承)
private只有本类有,别的都不能
练习题:
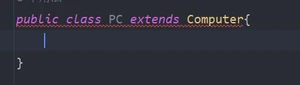
在Computer父类中设置了带参的构造器,无参的构造器被覆盖了,无默认的无参构造器。此时PC子类的构造器默认继承了Computer的无参构造器,就会报错
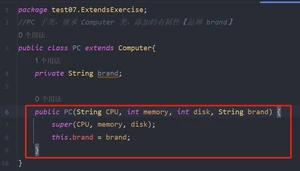
解决:创建一个子类的带参构造器,fn+alt+insert,这里IDEA根据继承的规则,自动把构造器的调用写好了
(体现了继承设计的基本思想,父类的构造器完成父类属性初始化,子类的构造器完成子类属性的初始化)

继承机制起到一个支撑的作用:

1.4重载overload
方法重载好处:一个方法名可以搞定好多功能, 减轻了起名、 记名 的麻烦
现实中:同一个对象对同一行为,传的内容不一样结果不一样
代码中:
在同一类中,方法名:要相同
形参列表:不相同(形参/数据 类型、个数、顺序 至少有一个不一样)
返回类型:无要求

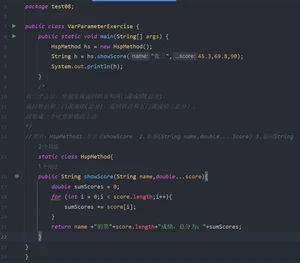
1.5可变参数
java 允许将同一个类中多个同名同功能但参数个数不同的方法,封装成一个方法。 就可以通过可变参数实现
语法: 访问修饰符 返回类型 方法名(数据类型... 形参名) { }

1.7作用域




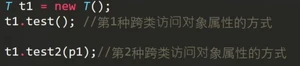
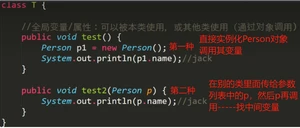
1.6重写override


2.子类书写过程中要一直遵循是父类的子类的规则,否则会报错
3.子类方法没办法修改父类的访问权限

重写的使用,子类中的方法和父类中的方法重写,子类方法调用时直接借助super.方法,再加上自己单独的属性就书写完成了

1.7多态polymorphic
方法或对象具有多种形态。是面向对象的第三大特征,多态是建立在封装和继承基础之上的。
多态的体现:
1)方法的多态:重写和重载就是体现多态
2) 对象的多态 (核心,困难,重点)


现实中多态:同一类型不同类型的对象对同一行为表现结果不同(切:厨师,医生,导演 都是人)
代码中多态:有继承,有重写,有父类类型的变量指向子类对象
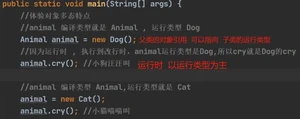
编译类型是(机器语言)编译器看到的类型,运行类型是java真正执行的时候运行的一个类型。
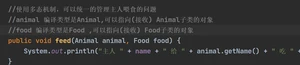
属性看编译类型,方法看运行类型

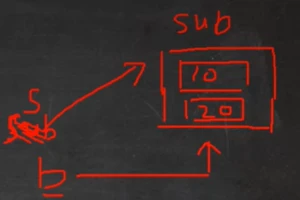
多态的前提是:两个对象(类)存在继承关系
多态的向上转型

多态向下转(强转)




![]()
不可以,上面指向的是Cat
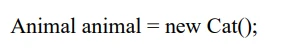
只有指向Dog,这里才可以强转
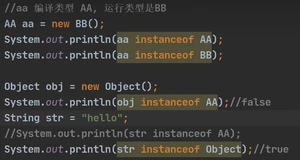
instanceOf 比较操作符,用于判断对象的运行类型是否为 XX 类型或 XX 类型的子类型
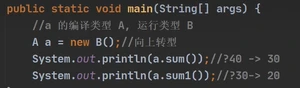
1.8动态绑定机制(非常重要)
调用对象方法时,该方法会和该对象的运行类型绑定
属性 没有动态绑定机制,就近原则使用

1.9API方法
1.字符串String方法
String StringBuffer StringBuilder 三个都可以操作字符串。
String底层不可以,每次变化都会生成一个新的字符串对象。安全的。
StringBuffer和StringBuilder它字符串可以变,每次变化不会生成新的空间。
StringBuffer它是线程安全的,因为它加了同步锁。而StringBuilder它是线程不安全。效率高。
一般我们使用StringBuffer就可以
str.length() 获取长度
insert(i,',')(参数1:第几位下标,参数2:'用什么分割')
str.charAt(1)
返回下标所在的字符(参数为int,返回char)
str.concat("呵呵")
追加字符(参数为string,返回string)
str.equals(str1)
是String的Object方法,也比较地址(内容一样统统equals())。看是否是重写,重写的话比较的是内容,没有重写比较的是地址和内容和"=="一样的意思。
==比较看是否是一个对象,值是否相等
基本数据类型判断:值是否相等
引用数据类型:要看地址和值
str.indexOf("1")
str.indexOf("1",2)
返回索引值,查找字符串所在的下标(有一个参数时就是要查找的字符)
从第几个索引位置开始,查找字符(参数一:要查找的字符,参数二:第几个下标开始)
str.lastIndexOf("1")
str.lastIndexOf("1",2)
从后查找,下标还是从0(前)开始
(参数一:要查找的字符,参数二:第几个下标开始)
str.substring(1,3)
截取字符(参数1:从下标几开始,参数2:到下标几结束)
str.compareTo(str1)
一样返回0
大返回正的数
小返回负的数
str2.split(",")
返回值为String,根据匹配给定的正则表达式来拆分字符串。
str.length()
返回值为int,字符串长度
str.trim()
用于删除字符串的 头尾 空白符。
str.isEmpty()
返回boolean类型:true/false。判断字符串是否为空。
contains()
判断字符串中是否包含指定的字符或字符串
replace()
通过用 newChar 字符替换字符串中出现的所有 searchChar 字符,并返回替换后的新字符串。
toUpperCase()
将小写字符转换为大写。返回转换后字符的大写形式,如果有的话;否则返回字符本身。
toLowerCase()
将大字符转换为小写。返回转换后字符的小写形式,如果有的话;否则返回字符本身。
"abc123".toCharArray()
将字符串转换为字符数组。
Str1.equalsIgnoreCase( Str4 )
将字符串与指定的对象比较,不考虑大小写。
reverse()
反转
delete(1,6)
删除指定位置的字符
append(“”)
追加
2.Integer和Charater类
3.Arrays数组工具类
sort
排序
copyof(数组,newLength)
复制并扩容
binarySearch()
二分查找
fill
填充
4.Object类
Student s1=new Student("秦桂祥2",16);
Student s2=new Student("秦桂祥",18);
equals()
//equals方法
System.out.println(s1==s2);//false
System.out.println(s1.equals(s2));//false.Object类中equals方法本地比较的还是两个对象的引用地址。
//如果想比较两个对象的内容,则需要重写Object类中equals方法。
//因为字符串类重写了equals
toString()
System.out.println(s1);//调用的toString方法。
System.out.println(s1.toString());//调用的toString方法。默认来自Object类。如果打印对象想显示自己的属性信息可以重写toString
hasCode()
System.out.println(s1);
System.out.println(s2);
System.out.println(s1==s2);//两个对象的hashcode相同,他们一定是同一个对象
//两个对象的hashcode相同,equals一定相同吗
(面试题)equals和==
==:它可以比较基本类型和引用类型。比较基本类型比较的是值,而比较引用类型比较的引用地址。
equals: 它只能比较引用类型。如果没有重写Object类中的equals方法它比较的还是引用地址。如果想比较值则需要重写equals。
1.10接口interface
接口是一个特殊的抽象类
特殊:接口中所有的方法都是抽象方法,而且接口中所有的属性都是静态常量。而且接口弥补了抽象类的单继承的缺点。---干爹
个人理解:接口就是指定一个规范,类来实现它,方便管理。
接口和抽象类一样也是无法创建类对象。 需要让其他类来实现该接口。类在实现接口时需要把接口中所有的抽象方法重写。
(面试题)2.0接口和抽象类区别
1.相同:接口和抽象类都无法创建对象,他们都是用于父亲和多态的体现。
2.不同:抽象类有构造方法,接口没有。
抽象类中可以没有抽象方法,而接口中都是抽象方法。JDK1.8以前
抽象类中可以有普通属性,接口中所有的属性都是静态常量。
一个类只能继承一个抽象类,但是却可以实现多个接口。
2.1包装类
万事万物皆为对象,基本类型。为了满足这种需求,为基本数据类型提供了包装类。类中会包含想要的功能方法。有这些方法我就可以对基本类型进行操作了。"123"-->整型123.
int-->Integer
byte-->Byte
short-->Short
long-->Long
double--->Double
float--->Float
boolean-->Boolean
char--->Character
自动装箱
装箱:把基本数据类型转化为包装类的过程
自动拆箱
3.1异常
1. 什么是异常?
异常就是程序在运行时出现的意外情况,而导致程序无法正常往下执行[终止了]
2. 为什么需要异常处理?
异常处理的目的就是想让程序继续执行。

我们发现上面再14行发生异常,而导致14行以下的内容都无法正常执行。从而导致程序再14终止了。我们应该处理这种异常。能让程序继续执行。
3. 异常处理的方式?
java中提供了两种异常处理的方式:
第一种:
try{
可能发生异常的代码
}catch(异常类型 对象){
捕获异常
}finally{
异常的出口
}
第二种: 抛出异常throws
处理完异常后我们的程序可以继续执行了.
finally关键字:
使用异常处理中,作为最终执行的代码。不管有没有异常都会执行finally中代码。
后期使用在资源关闭中。是否执行了return,finally也会被执行
注意: try{}可以finally单独使用。try{}finally{}//没有捕获异常。
异常的根类(一个公共的父类)是Throwable.
Throwable下有两个子类:
Exception: 异常类,我们程序员可以处理的异常。一般使用该异常就了。
Error: 错误类。这种异常程序员无法处理。比如内存溢出。
根据多态,再异常捕获时可以使用Exception异常来捕获。
注意:如果你使用多个catch 范围大的必须放在访问下的后面。
eg:对于try{……}catch子句的排列方式:父类异常在前,子类异常在后。(子类异常包含父类异常)
如果我们抛出的异常为RuntimeException下的异常。不要强制调用者处理。

4. throw关键字
我们前面讲解的异常,都是程序自己产生的异常对象。 我们也可以自己定义异常对象。并把该异常对象抛出。

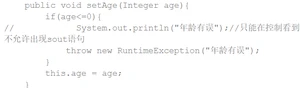
throw是在代码块内用来抛出具体异常的,而throws是在方法签名中用来声明可能抛出的异常类型的。
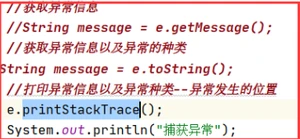
5. Exception异常类中常用的方法?
getMessage():获取异常信息
toString():获取异常信息以及异常种类
printStackTrace():打印异常信息以及异常种类和异常发生的位置
6. 自定义异常
当系统提供的异常类型无法满足客户需求时,程序员可以自己定义异常类型。目的可以达到见名知意
创建一个异常类并继承RuntimeException
public class AgeException extends RuntimeException {
//创建一个构造函数
public AgeException(String msg){
super(msg);
}
}
使用自定义的异常类
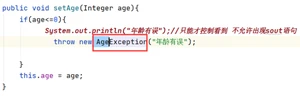
4.IO流
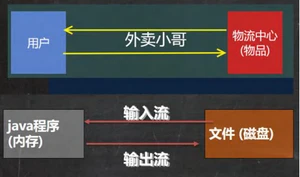
I/O是Input/Output的缩写,用于处理数据传输。如读/写文件、网络通讯等。
Java程序中,对于数据的输入和输出操作以"流(stream)"的方式进行。
java.io包下提供了各种”流“类和接口,用以获取不同种类单独数据,并提供方法输入或输出数据。
输入input:读取外部数据(磁盘、光盘等储存设备的数据)到程序(内存)中。
输出output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
file只能对文件进行操作,但是无法对文件中的内容进行操作。IO流是针对文件的内容操作的一个类集合。
流的方向:输入流和输出流
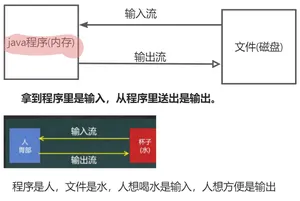
4.0 IO流中的File文件对象
获取文件的相关信息
getName:文件名、getAbsolutePath绝对路径、getParent父文件、length长度、exists判断是否存在、isFile是否为文件、isDirectory是否为目录(目录也是一种特殊的文件)
获取一个列表对象list();
获取一个目录下的所有文件和子目录 listFiles()
在java jdk关于对文件【目录和文件】的操作都封装到File类。该类中包含了文件的各种属性以及操作方法。该类放在jdk--java.io包下
创建文件对象:File file=new File("路径");
创建新文件: createNewFile();
创建目录: 一级mkdir() 多级mkdirs();
删除文件和空目录: delete();
重命名: renameTo(File file)
exists:判断文件或目录是否存在
boolean exists = file01.exists();
System.out.println("文件是否存在"+exists);
directory:判断文件是否为目录
boolean directory = file01.isDirectory();
System.out.println("该文件是否为目录:"+directory);
案例:
4.2流的分类

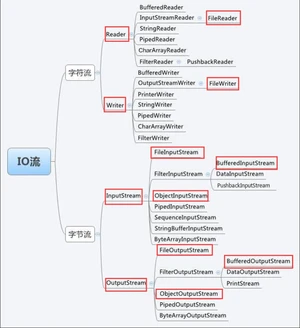
字符流:只能操作文字,.txt文本
字节流:文字、图片,视频,音频等都可以
IO流体系图
文件vs流
FileInputStream()字节输入流
使用 FileInputStream 读取文件,并将文件内容显示到控制台。
字节输入流的父类InputStream。
FileOutputStream()字节输出流
字节输出流的父类:OutputStream
1)使用 FileOutputStream 在 w.txt 文件,中写入 “hello,world”.
如果文件不存在,会创建文件(注意:前提是目录已经存在 )
2)编程完成图片/音乐 的拷贝
1. new FileOutputStream(filePath) 创建方式,当写入内容是,会覆盖原来的内容
2. new FileOutputStream(filePath, true) 创建方式,当写入内容是,是追加到文件后面
//写入字符串 String str = "hsp,world!"; //str.getBytes() 可以把 字符串-> 字节数组 //fileOutputStream.write(str.getBytes());
通过流完成文件的复制。(这种效率很慢)
先输入(要复制的对象地址)再输出(要复制到哪里的地址)。就是可完成复制。
FileReader()字符输入流
Reader它是字符输入流的一个父类,它也是抽象类,常见的子类FileReader.以字符为单位。
FileWrite()字符输出流
Write类,它是所有字符输出流的父类,输出的内容以字符为单位。它下面常用的子类FileWrite


缓冲流
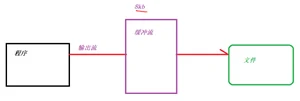
常用的缓冲流: BufferedInputStream 和BufferOutputStream 缓冲流是作用在流上。
对象流
操作java类的对象,把java类对象写入到文件中,或者从文件中读取写入的java对象。
ObjectOutputStream序列化:把内存中的java对象写入到文件中的过程
ObjectInputStream反序列化:把文件中的对象读取到内存中
5.集合
集合: 它就是一个容器,允许存放若干个对象元素。
数组: 它也是一个容器,它里面允许放在相同类型的元素。
数组缺陷: 它只能放置同一类型,它的长度是固定。而集合里面可以放置任意类型的元素,而且长度不限【int最大长度】。
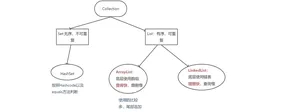
java中提供了很多集合接口和类。根据底层的结构不同。 它就是集合的体系结构。
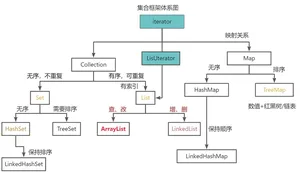
5.1Collection
他是单值集合的根(接口),如果想要使用Collection集合中的功能,需要创建该接口的子类。以ArrayList为例,集合既然是容器,无外乎包含的功能就是增、删、改、查。
5.2List:有序允许元素重复
Collection它是所有单值集合的根接口,它下面有两个子接口。List和Set.
List: 有序允许元素重复。
Set: 无序不可重复
5.3Set集合:无序不可重复
5.4ArayList查询效率快:名.get(索引值)
List的子类,具备list的特点之外,
还具备自己的特点: 它的底层使用数组,查询效率快:名.get(索引值),
缺点: 中间:插入和删除慢--因为设计到元素的位移.
5.5(面试题)LinkedList增删速度快:add()/remove()
它也属于List的子类,它的底层使用链表结构。特点: 增删速度快,查询速度慢。

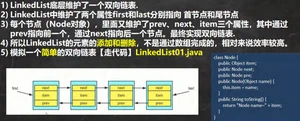
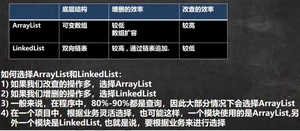
5.6ArrayList和LinkedList比较
5.7(面试题)HashSet无序,不允许重复
Set的子类,拥有和Set接口一样的方法。
底层使用hash表。按照hashcode以及equals方法比对判断元素是否重复的。
流程:先执行Hashcode方法,如果值不相同,则认为不同元素,不执行equals方法了,
如果值相同,则执行equals方法,
equals也相同,则认为相同元素。
5.8常用
5.9泛型
观察: 创建集合时<E> 他就是泛型标志, 限制集合中元素的类型。如果没有指定泛型,那么集合中可以存放任意类型的对象Object。
5.10 TreeSet:自动排序
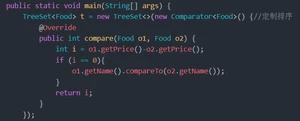
是set的子类,它的底层使用的是红黑二叉树,它里面的元素会自动按照ASCII码值的排序。
往TreeSet中添加一个对象,字符串实现Comparable接口,该接口是一个排序规则接口。我们需要为该类实现Comparable接口。
排序规则:返回一个int类型。
正整数:表示当前添加的元素比容器中要比较的元素大
负数:表示当前的元素比容器中的元素小。
0:表示相同的元素。
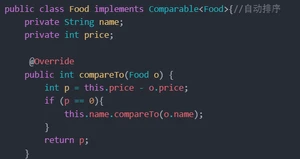
我们在创建Food类对象时,实现类排序规则的接口,如果你往TreeSet中添加的对象,是别人写好的类,没有实现排序规则的接口。如果别人写的类排序规则满足不了你的要求。比如按照字符串的长度排序。这时候就需要用到定制排序这种来写,以此来解决每个类都有独特的功能需求。
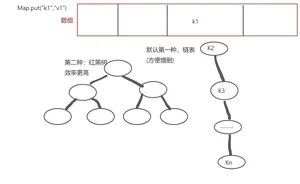
5.11 Map以及Map下的子类
上面的集合都是单值集合,而Map它是一个键值对集合。Map集合中的元素有key和value组成。底层实现类HashMap
Map中方法:---子类HashMap
- 存放元素: put(key,value)
- 获取Map元素个数: size()---返回类型int
- 根据key获取对应的value: get(key)
- 判断某个key是否在map中: containsKey()-----true/false
- 清空: clear()
- 根据key移除: remove()
- 获取map中所有key: keySet()
- 遍历Map对象
5.12(面试题)HashMap底层原理
JDK1.7底层使用的是数组+链表
JDK1.8以后底层使用数组+链表+红黑二叉树
根据key计算除Hash值,根据Hash值找到对应的数组位置,查看该位置是否存在元素。
如果该位置没有元素,则存在k---v;
如果有元素,比较equals,如果equals不同,hash冲突
如果hash冲突的个数比较多,使用红黑二叉树。链表转化数冲突的个数超过8个,数组长度超过64位。
5.13Collections工具类(针对集合类)
Collections类是Java中针对集合类的一个工具类,其中提供一系列静态方法。
工具类中所有的方法都是静态方法: 直接通过类名调用。
动态添加元素-addAll();
复制并覆盖相应索引的元素--copy();
用T元素替换掉集合中的所有的元素。fill(list1,T);
洗牌---打乱元素中的元素--shuffle(list2);
对集合排序----从小到大sort(list2);
---从大到小排序
Collections.sort(list2, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
二分查找---要求集合是有序的。如果找到返回该元素所在的下标.如果没有找到返回负数binarySearch(list2,3);
max、min、replace、replaceAll、reverse、。。。
sort()排序 binarySearch()二分查找 shuffle()洗牌。 fill填充 copy();
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/25145.html