
前言
最近,因为项目需要,将 TDengine 整合进入项目中进行使用。虽然之前也在前面的项目中多多少少用过,但抽了周末时间看了一番官网,并总结些记录及使用,物联网领域中的应用更是广泛了,如果想学习物联网领域,那么时序数据库的概念应该多少都有了解,而今天文章的主角--TDengine,更是时序数据库中的一颗巨星。
一、概述篇
1.1 概述
TDengine 是一款开源、云原生的时序数据库,专为物联网、工业互联网、金融、IT 运维监控等场景设计并优化。它能让大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据得到高效实时的处理,对业务的运行状态进行实时的监测、预警,从大数据中挖掘出商业价值。
在 2022 年 8 月,TD 推出了 3.0 版本(备注:2.x版本后续不再维护)。 3.x 的版本中,性能测试方面大幅度高于 InfluxDB 和 TimescaleDB,支持 10亿个设备采集数据,100个节点,支持存储与计算分离。因此,挺适合我们在物联网领域中进行集成使用的。
官网:www.taosdata.com/

1.2 基本概念
详见官网,这里的概念还是得理解清楚才能进行后续的表设计。
1.2.1 采集量(Metric)
采集值是指传感器、设备或其他类型采集点采集的物理量,比如电流、电压、温度,是随着时间变化的,数据类型可以是整型、浮点型、布尔型、字符串,随时间迁移,采集数据量越来越大。 也有称采集指标,也有人称采集点位。做物联网的应该都明白这个概念。
1.2.2 标签(Tag)
标签是静态的,比如设备地址,设备颜色,静态的,但是 TD 允许用户修改。
问题:修改标签后,原来存储的标签是原来值还是修改后的值?
1.2.3 数据采集点(Data Collection Point)
数据采集点是指按照预设时间周期或受事件触发采集物理量的硬件或软件。一个数据采集点可以采集一个或多个采集量,但这些采集量都是同一时刻采集的,具有相同的时间戳。
1.2.4 表(table)
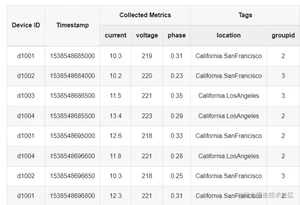 为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,比如表格中的 java零基础入门编写 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,比如表格中的 java零基础入门编写 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
- 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高。
如果采用传统的方式,将多个数据采集点的数据写入一张表,由于网络延时不可控,不同数据采集点的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个数据采集点的数据是难以保证连续存储在一起的。采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
总结:即一个采集点对应一张表
1.2.5 超级表
一个采集点一张表,导致表的数量巨大,而且要经常做到聚合操作?
因此,引入超级表的概念。
超级表是指某一特定类型的数据采集点的集合,同一类型的数据采集点,其表结构是完全一样的,但每个表的静态属性tag 是不一样的。
1.2.6 子表
通过超级表创建的表称为子表。查询可在子表和超级表上查询,如果从主表查询,TD 会对子表进行过滤,然后筛选出符合的子表再查询,这样的效率大大提升。
子表 VS 普通表
- 子表在正常表上加了静态标签,可以动态维护
- 子表一定属于一张超级表
- 子表与普通表无法互转
超级表 VS 子表
- 一张超级表包含多张子表,这些子表具有相同的采集量 Schema,但带有不同的标签值
- 不能通过子表调整数据,在超级表修改模式,立即对所有子表生效
- 超级表类似于模板,不能向超级表写入数据,只能从子表写入数据。
1.3 安装
在 centos7上安装服务端,然后在本机电脑上安装client端。 下载安装包,上传到服务器。
1、tar 解压目录
2、进入到安装包所在目录,先解压文件后,进入子目录,执行其中的 install.sh 安装脚本 以上服务端的安装就好了。
3、安装后,使用 systemctl 命令来启动 TDengine 的服务进程。
systemctl stop taosd 指令在执行后并不会马上停止 TDengine 服务,而是等待系统中必要的落盘工作正常完成,在数据量很大的情况下,这可能会消耗较长时间。
如果系统不支持 systemd,则进入 /usr/local/taos/bin/taosd 方式启动 TDengine 服务。
使用 taos 命令,进入命令行, 执行官网的案例 :
建立连接,windows 可与直接连接服务端进行使用。 TD 提供两种连接方式:
- 1、通过 taosAdapter 组件提供的 REST API 建立与 taosd 的连接,这种连接方式下简称 “REST 连接”。
- 2、通过客户端驱动程序 taosc 直接与服务端程序 taosd 建立连接,这种连接方式简称 “原生连接”。
区别:Rest 连接无需安装 taosc,性能下降 30%
下面介绍原生连接的方式,即我们需要在本机上装 client 软件。 默认安装路径为:C:TDengine,其中包括以下文件(目录):
- taos.exe:TDengine CLI 命令行程序
- taosadapter.exe:提供 RESTful 服务和接受其他多种软件写入请求的服务端可执行文件
- taosBenchmark.exe:TDengine 测试程序
- cfg : 配置文件目录
- driver: 应用驱动动态链接库
- examples: 示例程序 bash/C/C#/go/JDBC/Python/Node.js
- include: 头文件
- log : 日志文件
- unins000.exe: 卸载程序
需要我们配置 taos.cfg 文件,将 firstEP 修改为 TDengine 服务器的 End Point ,例如
firstEp mytd:6030
同时,在 host 目录下,C:Windowssystem32driversetchosts 新增 host 记录
192.168.31.102 mytd
执行 taos 命令: 发现下面bug
Failed to check Server Edition, Reason:0x:Fail to get table info, error: some vnode/qnode/mnode(s) out of service
原因是,没有修改服务端的域名。修改 linux 中 /etc/hosts 下新增 mytd 192.168.31.102。
本服务演示的软件版本为 3.0.7.0
二、TD 集成
2.1 开发指南
TD 的使用,要做下面几件事情。
- 1、确定 TD 的连接方式,例如使用 Java 导入依赖即可
- 2、根据自己的应用场景,确定数据模型。根据数据特征,决定建立一个还是多个库;分清静态标签、采集量、建立正确的超级表、建立子表
- 3、决定数据插入方式,TD 支持标准 SQL 写入,不用手工建表就可插入数据
- 4、可以做监测看板,使用 TD 3.0 的流式计算功能
- 5、可以使用数据订阅功能,当有新的数据插入时,就能获取通知,无需部署Kafka或其他软件(好功能!) 。
- 6、很多场景下,需要获取每个数据采集点的最新状态,建议采用 TD 的 Cache 功能,不用单独部署 Redis 等缓存软件(多种方案)。
- 7、可以自定义函数(UDF)来解决这个问题。
2.2 maven 项目测试
编写测试代码:
2.3 数据建模
在物联网场景中,一般有多种不同类型的采集设备,采集多种不同的物理量。
同一种采集设备类型,往往有多个设备分布在不同的地点。以智能电表为例子。
TDengine的创新:一个采集点一张表。
前提:需要建库、建超级表、建表、才能写入数据。

2.3.1 创建库
建议为数据特征相同的表创建一个库,每个库可以配置不同的存储策略。
- 如果数据不可靠,但是要求高,就单独创建库
- 数据可靠,单独创建库
2.3.2 引入超级表
一个数据采集点一张表,意味着 1000万智能电表对应 1000 万张表。
一个物联网系统,往往存在海量同类型的数据采集点,如何对这么多张表进行操作就是一个巨大的挑战。
超级表引入:为方便对同类型多表的操作。
创建超级表时,需提供:表名、表结构 Schema、标签 Schema
超级表的列分为两部分:
- 动态字段:采集的物理量动态的
- 静态字段:地理位置、设备组等
- 同时采集同表:一张超级表,包含的采集物理量必须是同时采集的,也就是说时间戳都是相同的。
-
- 也就是例如温湿传感器,它采集的数据是同时的,那就放在一张超级表里,但是一个设备,它有很多参数,采集的数据不是实时的,就不能放在一张表里
- 对一个类型的设备,可能存在多组物理量,每组物理量并不是同时采集的,则需要为每组物理量单独建一个超级表。因此,一个类型的设备,可能需要建立多个超级表。
- 系统里面有 N 个不同类型的设备,就需要建立至少 N 个超级表
- 一个系统可以有多个 DB 库,一个 DB 库里可以有一到多个超级表
2.3.3 创建子表
用户在写数据时,并不确定某个子表是否存在,此时,可使用自动建表语法来创建不存在的表,若该表已经存在则不会建立新表。
思考:多列模型 VS 单列模型
- TD 支持多列模型,也支持单列模型
- 同时采集同表采用多列模型:只要物理量是同一数据采集点同时采集的,这些量就可以作为不同列放在一张超级表里。
- 就是根据智能电表的案例(电流、电压等作为一个字段)
- 单列模型:每个物理量都单独创建表。比如电流、电压两个量,就建两张超级表。
TD的建议:
- 尽可能采用多列模型,因为插入效率以及存储效率更高;
- 对于有些场景,一个采集点的物理量的种类经常变化,这时可采用单例模型。
2.3.4 实战Demo
对同一张表,如果新插入记录的时间戳已经存在,则指定了新值的列会用新值覆盖旧值,而没有指定新值的列则不受影响。。
TD 的查询功能演示 : 单列 和 多列
- 函数avg
2.4 springboot 项目集成
1、新增依赖
2、修改双数据源配置
3、可以编写 mapper 层
4、xml 的案例代码
小结
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/19656.html