
Zookeeper基础入门-1【集群搭建】
- 一、Zookeeper 入门
-
- 1.1.概述
- 1.2.Zookeeper工作机制
- 1.3.Zookeeper特点
- 1.4.数据结构
- 1.5.应用场景
-
- 1.5.1.统一命名服务
- 1.5.2.统一配置管理
- 1.5.3.统一集群管理
- 1.5.4.服务器动态上下线
- 1.5.5.软负载均衡
- 1.6.Zookeeper官网
-
- 1.6.1.Zookeeper下载
- 1.6.2.历史版本
- 1.6.3.下载Linux 环境安装的tar包
- 二、Zookeeper安装【Centos7】
- 2.1.环境要求
-
- 2.1.1.安装JDK
- 2.1.2.上传apache-zookeeper-3.5.7-bin.tar.gz 安装包到/opt/module目录下
- 2.1.3.解压到指定目录
- 2.1.4.修改文件夹名称
- 2.2.配置修改
-
- 2.2.1.将zookeeper-3.5.7/conf 路径下的 zoo_sample.cfg 修改为 zoo.cfg
- 2.2.2.修改zookeeper数据文件存放目录
- 2.2.3.创建相关数据文件存放目录
- 2.3.操作Zookeeper
-
- 2.3.1.添加到环境变量
- 2.3.2.启动Zookeeper
- 2.3.3.查看进程是否启动
- 2.3.4.ZooKeeper服务端口为2181,查看服务已经启动
- 2.3.5.查看状态
- 2.3.6.启动客户端
- 2.3.7.退出客户端
- 2.3.8.停止Zookeeper
- 2.3.9.查看数据文件存放目录zkData
- 2.4.配置参数解读
-
- 2.4.1.tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
- 2.4.2.initLimit = 10:LF初始通信时限
- 2.4.3.syncLimit = 5:LF同步通信时限
- 2.4.4.dataDir:保存Zookeeper中的数据
- 2.4.5.clientPort = 2181:客户端连接端口,通常不做修改
- 三、Zookeeper 集群操作
-
- 3.1.集群操作
-
- 3.1.1.集群安装
-
- 3.1.1.1.集群规划
- 3.1.1.2.解压安装
- 3.1.1.3.配置服务器编号
-
- 3.1.1.3.1.创建相关数据文件存放目录 zkData
- 3.1.1.3.2.创建一个 myid 的文件【!!!】
- 3.1.1.3.3.拷贝配置好的 zookeeper 到其他机器上
- 3.1.1.4.配置zoo.cfg文件
-
- 3.1.1.4.1.拷贝配置文件zoo_sample.cfg 为zoo.cfg
- 3.1.1.4.2.修改zookeeper配置文件zoo.cfg【!!!】
- 3.1.1.4.3.配置参数解读【!!!】
- 3.1.1.4.4.同步zoo.cfg 配置文件
- 3.1.1.4.5.修改zkEnv.sh文件并同步,配置java环境变量
- 3.1.1.5.集群操作
-
- 3.1.1.5.1.分别启动Zookeeper
- 3.1.1.5.2.查看状态
- 3.1.2.选举机制(面试重点)
-
- 3.1.2.1.Zookeeper选举机制——第一次启动
- 3.1.2.2.Zookeeper选举机制——非第一次启动
- 3.1.3.ZK 集群启动停止脚本
-
- 3.1.3.1.在host128 创建脚本
- 3.1.3.2.脚本内容
- 3.1.3.3.增加脚本执行权限
- 3.1.3.4.Zookeeper 集群启动
- 3.1.3.5.Zookeeper 集群状态
- 3.1.3.6.Zookeeper 集群停止
- 3.1.4.显示集群的所有java进程状态jpsall 脚本
-
- 3.1.4.1.在host128 创建脚本
- 3.1.4.2.脚本内容
- 3.1.4.3.增加脚本执行权限
- 3.1.4.4.执行脚本
- 3.2. 客户端命令行操作
-
- 3.2.1.命令行基本语法
-
- 3.2.1.1.启动客户端
- 3.2.1.2.显示所有的操作命令
- 3.2.2.znode 节点数据信息
-
- 3.2.2.1.查看当前znode中所包含的内容
- 3.2.2.2.查看当前节点详细数据
- 3.2.3.节点类型(持久/短暂/有序号/无序号)
-
- 3.2.3.1.分别创建2个普通节点(永久节点 + 不带序号)
- 3.2.3.2.获得节点的值
- 3.2.3.3.创建带序号的节点(永久节点 + 带序号)
-
- 3.2.3.3.1.先创建一个普通的根节点/sanguo/weiguo
- 3.2.3.3.2.创建带序号的节点
- 3.2.3.4.创建短暂节点(短暂节点 + 不带序号 or 带序号)
-
- 3.2.3.4.1.创建短暂的不带序号的节点
- 3.2.3.4.2.创建短暂的带序号的节点
- 3.2.3.4.3.在当前客户端是能查看到的
- 3.2.3.4.4.退出当前客户端然后再重启客户端
- 3.2.3.4.5.再次查看根目录下短暂节点已经删除
- 3.2.3.5.修改节点数据值
- 3.2.4.监听器原理
-
- 3.2.4.1.监听原理详解
- 3.2.4.2.常见的监听
- 3.2.4.3.节点的值变化监听
- 3.2.4.4.节点的子节点变化监听(路径变化)
- 3.2.5.节点删除与查看
-
- 3.2.5.1.查看节点状态
- 3.2.5.2.删除节点
- 3.2.5.3.递归删除节点
- endl
一、Zookeeper 入门
1.1.概述
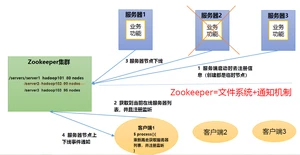
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的Apache 项目。
1.2.Zookeeper工作机制
Zookeeper从设计模式角度来理解:是一个基于设计的分布式服务管理框架,它,然后,一旦这些数据的状态发生变化,Zookeeper就将做出相应的反应。
1.3.Zookeeper特点
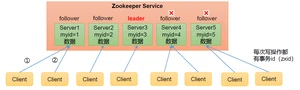
1) :一个领导者(Leader),多个跟随者(Follower)组成的集群。
2) 集群中只要有节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装。
3) :每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4) 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5) 数据更新,一次数据更新要么成功,要么失败。
6) ,在一定时间范围内,Client能读到最新数据。
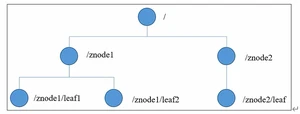
1.4.数据结构
1.5.应用场景
提供的服务包括:。
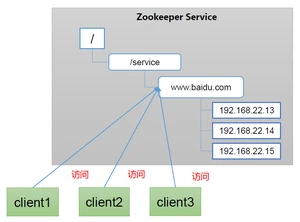
1.5.1.统一命名服务
1.5.2.统一配置管理
- 分布式环境下,配置文件同步非常常见。
- 一般要求一个集群中,所有节点的配置信息是一致的,比如 Kafka 集群。
- 对配置文件修改后,希望能够快速同步到各个节点上。
- 配置管理可交由ZooKeeper实现。
- 可将配置信息写入ZooKeeper上的一个Znode。
- 各个客户端服务器监听这个Znode。
- 一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
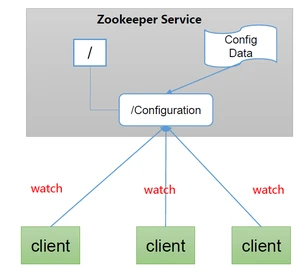
1.5.3.统一集群管理
- 分布式环境中,实时掌握每个节点的状态是必要的。
- 可根据节点实时状态做出一些调整。
- ZooKeeper可以实现实时监控节点状态变化
- 可将节点信息写入ZooKeeper上的一个ZNode。
- 监听这个ZNode可获取它的实时状态变化。
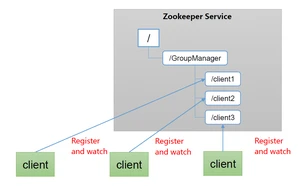
1.5.4.服务器动态上下线
- 客户端能实时洞察到服务器上下线的变化
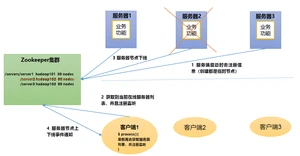
1.5.5.软负载均衡
- 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
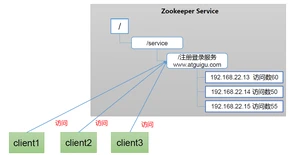
1.6.Zookeeper官网
Zookeeper官网:https://zookeeper.apache.org/
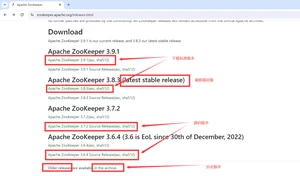
Zookeeper所有版本:https://archive.apache.org/dist/zookeeper/
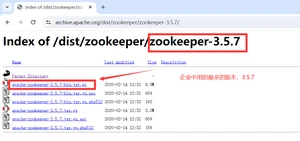
zookeeper-3.5.7:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
1.6.1.Zookeeper下载
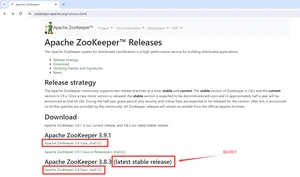
1.6.2.历史版本
1.6.3.下载Linux 环境安装的tar包
二、Zookeeper安装【Centos7】
2.1.环境要求
2.1.1.安装JDK

2.1.2.上传apache-zookeeper-3.5.7-bin.tar.gz 安装包到/opt/module目录下
2.1.3.解压到指定目录
2.1.4.修改文件夹名称
2.2.配置修改
2.2.1.将zookeeper-3.5.7/conf 路径下的 zoo_sample.cfg 修改为 zoo.cfg
2.2.2.修改zookeeper数据文件存放目录
2.2.3.创建相关数据文件存放目录
2.3.操作Zookeeper
2.3.1.添加到环境变量
2.3.2.启动Zookeeper

2.3.3.查看进程是否启动
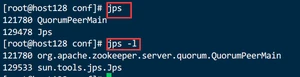
2.3.4.ZooKeeper服务端口为2181,查看服务已经启动

2.3.5.查看状态
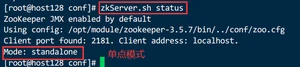
2.3.6.启动客户端
2.3.7.退出客户端
2.3.8.停止Zookeeper
2.3.9.查看数据文件存放目录zkData
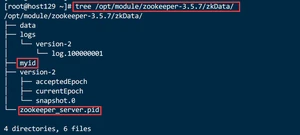
2.4.配置参数解读
2.4.1.tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
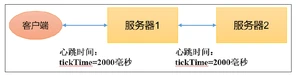
2.4.2.initLimit = 10:LF初始通信时限

Leader和Follower时能容忍的最多心跳数(tickTime的数量)
2.4.3.syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
2.4.4.dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
2.4.5.clientPort = 2181:客户端连接端口,通常不做修改
三、Zookeeper 集群操作
3.1.集群操作
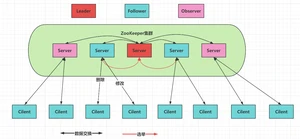
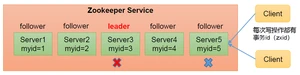
在ZooKeeper集群服中务中有三个角色:
:
- 处理事务请求
- 集群内部各服务器的调度者
:
- 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与Leader选举投票
:
- 处理客户端非事务请求,转发事务请求给Leader服务器
3.1.1.集群安装
3.1.1.1.集群规划
在host128、host129 和host130 三个节点上都部署Zookeeper
思考:如果是 10 台服务器,需要部署多少台 Zookeeper?
3.1.1.2.解压安装
3.1.1.3.配置服务器编号
3.1.1.3.1.创建相关数据文件存放目录 zkData
3.1.1.3.2.创建一个 myid 的文件【!!!】
3.1.1.3.3.拷贝配置好的 zookeeper 到其他机器上
,需要编辑集群分发脚本
并分别在host129、host130 上修改myid 文件中内容为 2、3
3.1.1.4.配置zoo.cfg文件
3.1.1.4.1.拷贝配置文件zoo_sample.cfg 为zoo.cfg
3.1.1.4.2.修改zookeeper配置文件zoo.cfg【!!!】
3.1.1.4.3.配置参数解读【!!!】
3.1.1.4.4.同步zoo.cfg 配置文件
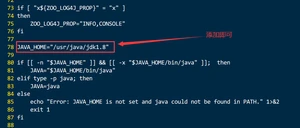
3.1.1.4.5.修改zkEnv.sh文件并同步,配置java环境变量
不修改容易报错:JAVA_HOME is not set and java could not be found in PATH.
3.1.1.5.集群操作
3.1.1.5.1.分别启动Zookeeper
3.1.1.5.2.查看状态

3.1.2.选举机制(面试重点)
3.1.2.1.Zookeeper选举机制——第一次启动
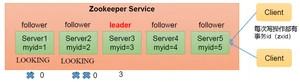
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),,服务器1状态保持为;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1票数0票,服务器2票数2票,没有半数以上结果,,服务器1,2状态保持;
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选。,;
(4),发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并;
(5)服务器5启动,同4一样当小弟。
3.1.2.2.Zookeeper选举机制——非第一次启动
(1)当zookeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
- 服务器初始化启动
- 服务器运行期间无法和leader保持连接
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
- 集群中本来就已经存在一个Leader
对于这种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。 - (重点)
假设ZooKeeper由5台服务器组成,SID分别为、、3、、5,ZXID分别为、、8、、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。最后选了服务器2。

3.1.3.ZK 集群启动停止脚本
3.1.3.1.在host128 创建脚本
3.1.3.2.脚本内容
3.1.3.3.增加脚本执行权限
3.1.3.4.Zookeeper 集群启动
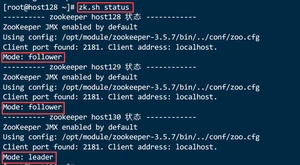
3.1.3.5.Zookeeper 集群状态
3.1.3.6.Zookeeper 集群停止
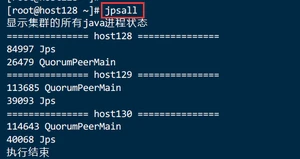
3.1.4.显示集群的所有java进程状态jpsall 脚本
3.1.4.1.在host128 创建脚本
3.1.4.2.脚本内容
3.1.4.3.增加脚本执行权限
3.1.4.4.执行脚本
3.2. 客户端命令行操作
3.2.1.命令行基本语法
-w 监听子节点变化
-s 附加次级信息create普通创建
-s 含有序列
-e 临时(重启或者超时消失)get path获得节点的值 [可监听]
-w 监听节点内容变化
-s 附加次级信息set java zookeeper基础设置节点的具体值stat查看节点状态delete删除节点deleteall递归删除节点
3.2.1.1.启动客户端
3.2.1.2.显示所有的操作命令
3.2.2.znode 节点数据信息
3.2.2.1.查看当前znode中所包含的内容
3.2.2.2.查看当前节点详细数据
:每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。
事务 ID 是 ZooKeeper 中所有修改总的次序。
每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
3.2.3.节点类型(持久/短暂/有序号/无序号)
- 持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除
- 短暂(Ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
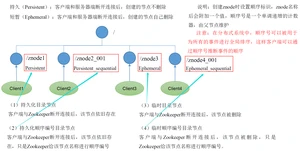
说明:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
3.2.3.1.分别创建2个普通节点(永久节点 + 不带序号)
3.2.3.2.获得节点的值
3.2.3.3.创建带序号的节点(永久节点 + 带序号)
3.2.3.3.1.先创建一个普通的根节点/sanguo/weiguo
3.2.3.3.2.创建带序号的节点
3.2.3.4.创建短暂节点(短暂节点 + 不带序号 or 带序号)
3.2.3.4.1.创建短暂的不带序号的节点
3.2.3.4.2.创建短暂的带序号的节点
3.2.3.4.3.在当前客户端是能查看到的
3.2.3.4.4.退出当前客户端然后再重启客户端
3.2.3.4.5.再次查看根目录下短暂节点已经删除
3.2.3.5.修改节点数据值
3.2.4.监听器原理
3.2.4.1.监听原理详解
1) 首先要有一个main()线程
2) 在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个,一个。
3) 通过connect线程将注册的监听事件发送给Zookeeper。
4) 在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中,表示这个服务器中的/path,即根目录这个路径被客户端监听了;
5) Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程。
6) listener线程内部调用了process()方法,采取相应的措施,例如更新服务器列表等。

3.2.4.2.常见的监听
1) 监听节点数据的变化
2) 监听子节点增减的变化
3.2.4.3.节点的值变化监听
(1)在host129 主机上注册监听/sanguo 节点数据变化
(2)在host130 主机上修改/sanguo 节点的数据
(3)观察host129 主机收到数据变化的监听
注意:在host130 再多次修改/sanguo的值,host129上不会再收到监听。
因为,只能。想再次监听,需要。
3.2.4.4.节点的子节点变化监听(路径变化)
(1)在host129 主机上注册监听/sanguo 节点的子节点变化
(2)在host130 主机/sanguo 节点上创建子节点
(3)观察host129 主机收到子节点变化的监听
注意:节点的路径变化,也是,。想多次生效,就需要。
3.2.5.节点删除与查看
3.2.5.1.查看节点状态
3.2.5.2.删除节点
3.2.5.3.递归删除节点
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/h6javajc/1782.html