
Redis Cluster是Redis的自带的官方分布式解决方案,提供数据分片、高可用功能,在3.0版本正式推出。
使用Redis Cluster能解决负载均衡的问题,内部采用哈希分片规则:
基础架构图如下所示:
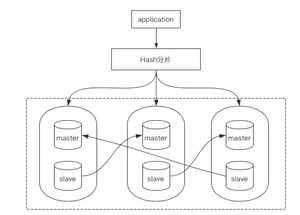
图中最大的虚线部分为一个Cluster集群,由6个Redis实例组成。
整个Cluster集群中有16384个槽位,必须要将这些槽位分别规划在3台Master中。
如果有任意1个槽位没有被分配,则集群创建不成功。
当集群中任意一个Master尝试进行写入操作后,会通过Hash算法计算出该条数据应该落在哪一个Master节点上。
如下图所示:
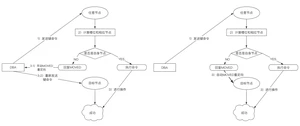
情况1:如果你未指定任何参数就进行写入,如在Master1上写入数据,经过内部计算发现该数据应该在Master2上写入时,会提示你应该进入Master2写入该条数据,执行并不会成功
情况2:如果你指定了一个特定参数进行写入,如在Master1上写入数据,经过内部计算发现该数据应该在Master2上写入时,会自动将写入环境重定向至Master2,执行成功
同理,读取数据也是这样,这个过程叫做MOVED重定向,如果你是情况1进行操作则必须手动进行重定向,情况2则会自动进行重定向。
集群中各个节点的信息是互通的,这种现象由Gossip(流言)协议产生。
Gossip协议规定每个集群节点之间互相交换信息,使其能够彼此知道对方的状态。
在通信建立时,集群中的每一个节点都会单独的开辟一个TCP通道,用于与其他节点进行通信,这个通信端口会在基础端口上+10000。
通信建立成功后,每个节点在固定周期内通过特定规则选择节点来发送ping消息(心跳机制)。
当收到ping消息的节点则会使用pong消息作为回应,也就是说,当有一个新节点加入后,一瞬间集群中所有的其他节点也能够获取到该信息。
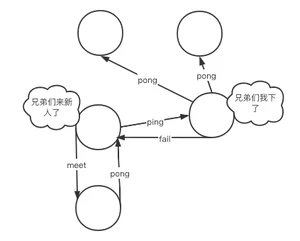
Gossip协议的主要职责就是进行集群中节点的信息交换,常见的Gossip协议消息有以下几点区分:
- meet:用于通知新节点加入,消息发送者通知接受者加入到当前集群
- ping:集群内每个节点与其他节点进行心跳检测的命令,用于检测其他节点是否在线,除此之外还能交换其他额外信息
- pong:用于回复meet以及ping信息,表示已收到,能够正常通行。此外还能进行群发更新节点状态
- fail:当其他节点收到fail消息后立马把对应节点更新为下线状态,此时集群开始进行故障转移
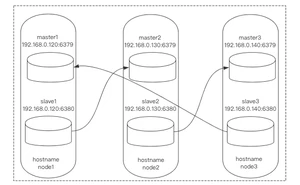
3台服务器,每台服务器开启2台实例构建基础主从。
服务器采用centos7.3,Redis版本为6.2.1
地址规划与结构图如下:
在每个节点hosts文件中加入以下内容;
为所有节点下载Redis:
为所有节点配置目录:
所有节点进行解压:
所有节点进行编译安装Redis:
书写集群配置文件,注意!Redis普通服务会有2套配置文件,一套为普通服务配置文件,一套为集群服务配置文件,我们这里是做的集群,所以书写的集群配置文件,共6份:
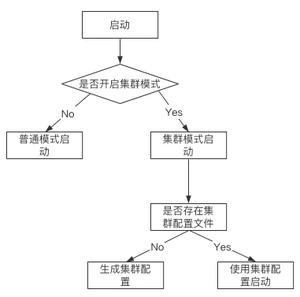
在启动集群时,会按照Redis服务配置文件的配置项判断是否启动集群模式,如图所示:
每个节点上执行以下2条命令进行服务启动:
同时,查看一下集群节点配置文件,会发现生成了一组集群信息,每个Redis服务都是不同的:
现在虽然说每个服务都成功启动了,但是彼此之间并没有任何联系。
所以下一步要做的就是将6个服务加入至一个集群中,如下操作示例:
查看当前集群所有的节点:
查看端口监听,可以发现Gossip监听的1000+端口出现了,此时代表集群各个节点之间已经能互相通信了:
6个服务之间并没有任何主从关系,所以现在进行主从配置,记录下上面cluster nodes命令输出的node-id信息,只记录主节点:
首先是node1的6380,将它映射到node2的6379:
然后是node2的6380,将它映射到node3的6379:
最后是node3的6380,将它映射到node1的6379:
查看集群节点信息,内容有精简:
接下来我们要开始分配槽位了,为了考虑今后的写入操作能分配均匀,槽位也要进行均匀分配。
仅在Master上进行分配,从库不进行分配,仅做主库的备份和读库使用。
使用python计算每个master节点分多少槽位:
槽位分配情况如下,槽位号从0开始,到16383结束,共16384个槽位:
开始分配:
检查槽位是否分配正确,这里进行内容截取:
使用以下命令检查集群状态是否ok,如果槽位全部分配完毕应该是ok,不然的话就检查你分配槽位时是否输错了数量:
现在我们在node1的master节点上进行写入:
它会提示你去node2的master上进行写入。
这个就是MOVED重定向。
如何解决这个问题?其实在登录的时候加上参数-c即可,-c参数无所谓你的Redis是否是集群模式,建议任何登录操作都加上,这样即使是Redis集群也会自动进行MOVED重定向:
一并对主从进行验证,这条数据是写入至了node3的Master中,我们登录node2的Slave中进行查看:
模拟node1的6379下线宕机,此时应该由node3的6380接管它的工作:
登录集群任意节点查看目前的集群节点信息:
重启node1的6379:
登录node1的6379,发现他已经自动的进行上线了,并且作为node3中6380的从库:
以下是集群中常用的可执行命令,命令执行格式为:
命令如下,未全,如果想了解更多请执行cluster help操作:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/8504.html