
}
GET my_index/_search
{
"query": {
"term": {
"status_code": "NULL"
}
}
}
文档 1可以被搜索到,因为 status_code的值为 null,文档 2 不可以被搜索到,因为 status_code为空数组,但是不是 null。
position_increment_gap
文本数组元素之间位置信息添加的额外值。
举例,一个字段的值为数组类型:"names": [ "John Abraham", "Lincoln Smith"]为了区别第一个字段和第二个字段,Abraham和 Lincoln在索引中有一个间
距,默认是 100。例子如下,这是查询”Abraham Lincoln”是查不到的:
PUT my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
GET my_index/groups/_search
{
"query": {
"match_phrase": {
"names": {
"query": "Abraham Lincoln"
}}}}
指定间距大于 10 0 可以查询到:
GET my_index/groups/_search
{
"query": {
"match_phrase": {
"names": {
"query": "Abraham Lincoln",
"slop": 101
}}}}
想要调整这个值,在 mapping中通过 position_increment_gap 参数指定间距即可。
properties
Object或者 nested类型,下面还有嵌套类型,可以通过 properties 参数指定。
比如:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"manager": {
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
},
"employees": {
"type": "nested",
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}}}}}}
对应的文档结构:
PUT my_index/my_type/1
{
"region": "US",
"manager": {
"name": "Alice White",
"age": 30
},
"employees": [
{
"name": "John Smith",
"age": 34
},
{
"name": "Peter Brown",
"age": 26
}
]
}
我们可以看看:get /open-soft/_doc/1
大体分为五种类型:身份(标识)元数据、索引元数据、文档元数据、路由元数据以及其他类型的元数据,当然不是每个文档这些元字段都有的。
身份(标识)元数据
_index:文档所属索引 , 自动被索引,可被查询,聚合,排序使用,或者脚本里访问
_type:文档所属类型,自动被索引,可被查询,聚合,排序使用,或者脚本里访问
_id:文档的唯一标识,建索引时候传入 ,不被索引,可通过_uid被查询,脚本里使用,不能参与聚合或排序
_uid:由_type和_id字段组成,自动被索引 ,可被查询,聚合,排序使用,或者脚本里访问,6.0.0版本后已废止。
索引元数据
_all:自动组合所有的字段值,以空格分割,可以指定分器词索引,但是整个值不被存储,所以此字段仅仅能被搜索,不能获取到具体的值。6.0.0版本后已废止。
_field_names:索引了每个字段的名字,可以包含 null值,可以通过 exists查询或 missing查询方法来校验特定的字段
文档元数据
_source : 一个 doc的原生的 json 数据,不会被索引,用于获取提取字段值,启动此字段,索引体积会变大,如果既想使用此字段又想兼顾索引体积,可以开启索引压缩。
_source是可以被禁用的,不过禁用之后部分功能不再支持,这些功能包括:部分 update api、运行时高亮搜索结果
索引重建、修改 mapping以及分词、索引升级
debug查询或者聚合语句
索引自动修复
_size:整个_source 字段的字节数大小,需要单独安装一个 mapper-size插件才能展示。
路由元数据
_routing:一个 doc可以被路由到指定的 shard上。
_meta:一般用来存储应用相关的元信息。
其他
例如:
put /open-soft/_mapping
{
"_meta": {
"class": "cn.enjoyedu.User",
"version": {"min": "1.0", "max": "1.3"}
}
}
在 es 中,索引和文档是 REST 接口操作的最基本资源,所以对索引和文档的管理也是我们必须要知道的。索引一般是以索引名称出现在 REST请求操作的资源路径上,而文档是以文档 ID 为标识出现在资源路径上。映射类型_doc 也可以认为是一种资源,但在 es7 中废除了映射类型,所以可以_doc 也视为一种接口。
索引的管理
在前面的学习中我们已经知道,GET 用来获取资源,PUT 用来更新资源,DELETE用来删除资源。所以对索引,GET用来查看索引,PUT用来创建索引,DELETE用来删除索引,还有一个 HEAD 请求,用来检验索引是否存在。除此之外,对索引的管理还有
列出所有索引
GET /_cat/indices?v
关闭索引和打开
POST /open-soft/_close、、
除了删除索引,还可以选择关闭它们。如果关闭了一个索引,就无法通过Elasticsearch来读取和写人其中的数据,直到再次打开它。
在现实世界中,最好永久地保存应用日志,以防要查看很久之前的信息。另一方面,在 Elasticsearch 中存放大量数据需要增加资源。对于这种使用案例,关闭旧的索引非常有意义。你可能并不需要那些数据,但是也不想删除它们。
一旦索引被关闭,它在 Elasticsearch 内存中唯-的痕迹是其元数据,如名字
以及分片的位置。如果有足够的磁盘空间,而且也不确定是否需要在那个数据中再次搜索,关闭索引要比删除索引更好。关闭它们会让你非常安心,永远可以重新打开被关闭的索引,然后在其中再次搜索。
重新打开 POST /open-soft/_open
配置索引
通过 settings参数配置索引,索引的所有配置项都以“index”开头。索引的管理分为静态设置和动态设置两种。
静态设置
只能在索引创建时或在状态为 closed index(闭合索引)上设置,主要配置索引主分片、压缩编码、路由等相关信息
index.number_of_shards主分片数,默认为 5.只能在创建索引时设置,不能修改
index.shard.check_on_startup 是否应在索引打开前检查分片是否损坏,当检查到分片损坏将禁止分片被打开。false:默认值;checksum:检查物理损坏;true:检查物理和逻辑损坏,这将消耗大量内存和 CPU;fix:检查物理和逻辑损坏。
有损坏的分片将被集群自动删除,这可能导致数据丢失
index.routing_partition_size 自定义路由值可以转发的目的分片数。默认为 1,只能在索引创建时设置。此值必须小于 index.number_of_shards
index.codec 默认使用 LZ4压缩方式存储数据,也可以设置为
best_compression,它使用 DEFLATE 方式以牺牲字段存储性能为代价来获得更高的压缩比例。
如:
put test1{
"settings":{
"index.number_of_shards":3,
"index.codec":"best_compression"
}
}
动态设置
通过接口“_settings”进行,同时查询配置也通过这个接口进行,比如:get _settings
get /open-soft/_settings
get /open-soft,test1/_settings
配置索引则通过:
put test1/_settings
{
"refresh_interval":"2s"
}
常用的配置参数如下:
index.number_of_replicas 每个主分片的副本数。默认为 1
index.auto_expand_replicas 基于可用节点的数量自动分配副本数量,默认为false(即禁用此功能)
index.refresh_interval 执行刷新操作的频率。默认为 1s。可以设置为 -1 以禁用刷新。
index.max_result_window 用于索引搜索的 from+size 的最大值。默认为10000
index.blocks.read_only 设置为 true 使索引和索引元数据为只读,false 为允许写入和元数据更改。
index.blocks.read 设置为 true 可禁用对索引的读取操作
index.blocks.write 设置为 true 可禁用对索引的写入操作
index.blocks.metadata 设置为 true 可禁用索引元数据的读取和写入
index.max_refresh_listeners 索引的每个分片上可用的最大刷新侦听器数index.max_docvalue_fields_search 一次查询最多包含开启 doc_values 字段
的个数,默认为 100
index.max_script_fields 查询中允许的最大 script_fields数量。默认为 32。
index.max_terms_count 可以在 terms 查询中使用的术语的最大数量。默认为65536。
index.routing.allocation.enable 控制索引分片分配。All(所有分片)、primaries(主分片)、new_primaries(新创建分片)、none(不分片)
index.routing.rebalance.enable 索引的分片重新平衡机制。all、primaries、replicas、none
index.gc_deletes 文档删除后(删除后版本号)还可以存活的周期,默认
为 60s
index.max_regex_length用于正在表达式查询(regex query)正在表达式长度,默认为 1000
配置映射
通过_mapping 接口进行,在我们前面的章节中,已经展示过了。
get /open-soft/_mapping
或者只看某个字段的属性:
get /open-soft/_mapping/field/lang
修改映射,当然就是通过 put或者 post方法了。但是要注意,已经存在的映射只能添加字段或者字段的多类型。但是字段创建后就不能删除,大多数参数也不能修改,可以改的是 ignore_above。所以设计索引时要做好规划,至少初始时的必要字段要规划好。
增加文档
增加文档,我们在前面的章节已经知道了,比如:
put /open-soft/_doc/1
{
"name": "Apache Hadoop",
"lang": "Java",
"corp": "Apache",
"stars":200
}
如果增加文档时,在 Elasticsearch中如果有相同 ID的文档存在,则更新此文档,比如执行
put /open-soft/_doc/1
{
"name": "Apache Hadoop2",
"lang": "Java8",
"corp": "Apache",
"stars":300
}
则会发现已有文档的内容被更新了
文档的 id
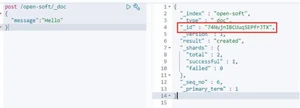
当创建文档的时候,如果不指定 ID,系统会自动创建 ID。自动生成的 ID 是一个不会重复的随机数。使用 GUID 算法,可以保证在分布式环境下,不同节点同一时间创建的_id一定是不冲突的。比如:
post /open-soft/_doc
{
"message":"Hello"
}
查询文档
get /open-soft/_doc/
更新文档
前面我们用 put方法更新了已经存在的文档,但是可以看见他是整体更新文档,如果我们要更新文档中的某个字段怎么办?需要使用_update接口。
post /open-soft/_update/1/
{
"doc":{
"year": 2016
}
}
如果文档中存在 year字段,更新 year 字段的值,如果不存在 year 字段,则会新增 year字段,并将值设为 2016。
update 接口在文档不存在时提示错误,如果希望在文档不存在时创建文档,则可以在请求中添加 upsert参数或 doc_as_upsert 参数,例如:
POST /open-soft/_update/5
{
"doc": {
"year": "2020"
},
"upsert":{
"name" : "Enjoyedu Framework",
"corp" : "enjoyedu "
}
}
或
POST /open-soft/_update/6
{
"doc": {
"year": "2020"
},
"doc_as_upsert" : true
}
upsert参数定义了创建新文档使用的文档内容,而 doc_as_upsert 参数的含义是直接使用 doc参数中的内容作为创建文档时使用的文档内容。
删除文档
delete /open-soft/_doc/1
为了方便我们学习,我们导入 kibana 为我们提供的范例数据。
目前为止,我们已经探索了如何将数据放入 Elasticsearch,现在来讨论下如何将数据从 Elasticsearch中拿出来,那就是通过搜索。毕竟,如果不能搜索数据,那么将其放入搜索引擎的意义又何在呢?幸运的是,Elasticsearch 提供了丰富的接口来搜索数据,涵盖了 Lucene 所有的搜索功能。因为 Elasticsearch允许构建搜索请求的格式很灵活,请求的构建有无限的可能性。要了解哪些查询和过滤器的组合适用于你的数据,**的方式就是进行实验,因此不要害怕在项目的数据上尝试这些组合,这样才能弄清哪些更适合你的需求。
所有的 REST搜索请求使用_search 接口,既可以是 GET请求,也可以是 POST请求,也可以通过在搜索 URL 中指定索引来限制范围。
_search 接口有两种请求方法,一种是基于 URI 的请求方式,另一种是基于请求体的方式,无论哪种,他们执行的语法都是基于 DSL(ES 为我们定义的查询语言,基于 JSON的查询语言),只是形式上不同。我们会基于请求体的方式来学习。比如说:
get kibana_sample_data_flights/_search
{
"query":{
"match_all":{}
}
}
或
get kibana_sample_data_flights/_search
{
"query":{
"match_none":{}
}
}
当然上面的查询没什么太多的用处,因为他们分别代表匹配所有和全不匹配。
所以我们经常要使用各种语法来进行查询,一旦选择了要搜索的索引,就需要配置搜索请求中最为重要的模块。这些模块涉及文档返回的数量,选择**的文档返回,以及配置不希望哪些文档出现在结果中等等。
■ query-这是搜索请求中最重要的组成部分,它配置了基于评分返回的**文档,也包括了你不希望返回哪些文档。
■ size-代表了返回文档的数量。
■ from-和 size 一起使用,from 用于分页操作。需要注意的是,为了确定第2页的 10 项结果,Elasticsearch 必须要计算前 20 个结果。如果结果集合不断增加,获取某些靠后的翻页将会成为代价高昂的操作。
■ _source指定_ source 字段如何返回。默认是返回完整的_ source字段。
通过配置_ source,将过滤返回的字段。如果索引的文档很大,而且无须结果中的全部内容,就使用这个功能。请注意,如果想使用它,就不能在索引映射中关闭_source 字段。
■ sort默认的排序是基于文档的得分。如果并不关心得分,或者期望许多文档的得分相同,添加额外的 sort将帮助你控制哪些文档被返回。
命名适宜的 from和 size字段,用于指定结果的开始点,以及每“页"结果的数量。举个例子,如果发送的 from 值是 7,size值是 5,那么 Elasticsearch 将返回第8、9、10、11 和 12项结果(由于 from 参数是从 0开始,指定 7 就是从第 8项结果开始)。如果没有发送这两个参数,Elasticsearch 默认从第一项结果开始(第 0 项结果),在回复中返回 10项结果。
例如
get kibana_sample_data_flights/_search
{
"from":100,
"size":20,
"query":{
"term":{
"DestCountry":"CN"
}
}
}
但是注意,from与 size 的和不能超过 index. max_result_window 这个索引配置项设置的值。默认情况下这个配置项的值为 10000,所以如果要查询 10000 条以后的文档,就必须要增加这个配置值。例如,要检索第 10000 条开始的 200条数据,这个参数的值必须要大于 10200,否则将会抛出类似“Result window is toolarge'的异常。
由此可见,Elasticsearch 在使用 from 和 size处理分页问题时会将所有数据全部取出来,然后再截取用户指定范围的数据返回。所以在查询非常靠后的数据时,即使使用了 from和 size定义的分页机制依然有内存溢出的可能,而 max_result_ window设置的 10000条则是对 Elastiesearch 的一.种保护机制。
那么 Elasticsearch 为什么要这么设计呢?首先,在互联网时代的数据检索应该通过相似度算法,提高检索结果与用户期望的附和度,而不应该让用户在检索结果中自己挑选满意的数据。以互联网搜索为例,用户在浏览搜索结果时很少会看到第 3页以后的内容。假如用户在翻到第 10000 条数据时还没有找到需要的结果,那么他对这个搜索引擎一定会非常失望。
_source 参数
指定映射的数组,而不是字段的数组。通过在 sort 中指定字段列表或者是字段映射,可以在任意数量的字段上进行排序。
例如:
get kibana_sample_data_flights/_search
{
"from":100,
"size":20,
"query":{
"match_all":{}
},
"_source":["Origin*","*Weather"],
"sort":[{"DistanceKilometers":"asc"},{"FlightNum":"desc"}]
}
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/6213.html