
参考文章:https://www.cnblogs.com/Luv-GEM/p/10884493.html
在TextRank之前我们需要先了解一下PageRank算法。事实上它启发了TextRank!PageRank主要用于对在线搜索结果中的网页进行排序。
PageRank对于每个网页页面都给出一个正实数,表示网页的重要程度,PageRank值越高,表示网页越重要,在互联网搜索的排序中越可能被排在前面。
假设整个互联网是一个有向图,节点是网页,每条边是转移概率。网页浏览者在每个页面上依照连接出去的超链接,以等概率跳转到下一个网页,并且在网页上持续不断地进行这样的随机跳转,这个过程形成了一阶马尔科夫链,比如下图:

每个笑脸是一个网页,既有其他网页跳转到该网页,该网页也会跳转到其他网页。在不断地跳转之后,这个马尔科夫链会形成一个平稳分布,而PageRank就是这个平稳分布,每个网页的PageRank值就是平稳概率。
PageRank的核心公式是PageRank值的计算公式。公式如下:
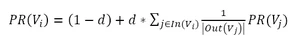
其中,PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合。
这个公式来自于《统计学习方法》,等号右边的平滑项(通过某种处理,避免一些突变的畸形值,尽可能接近实际情况)不是(1-d),而是(1-d)/n。
阻尼系数d(damping factor)的意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。1-d就是用户停止点击,随机跳到新URL的概率。
加平滑项是因为有些网页没有跳出去的链接,那么转移到其他网页的概率将会是0,这样就无法保证存在马尔科夫链的平稳分布。
于是,我们假设网页以等概率(1/n)跳转到任何网页,再按照阻尼系数d,对这个等概率(1/n)与存在链接的网页的转移概率进行线性组合,那么马尔科夫链一定存在平稳分布,一定可以得到网页的PageRank值。
所以PageRank的定义意味着网页浏览者按照以下方式在网上随机游走:以概率d按照存在的超链接随机跳转,以等概率从超链接跳转到下一个页面;或以概率(1-d)进行完全随机跳转,这时以等概率(1/n)跳转到任意网页。
PageRank的计算是一个迭代过程,先假设一个初始的PageRank分布,通过迭代,不断计算所有网页的PageRank值,直到收敛为止,也就是:
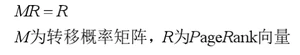
这篇文章里有详细的例子:https://www.cnblogs.com/cuiyubo/p/10175268.html
两种算法的相似之处:
- 用句子代替网页
- 任意两个句子的相似性等价于网页转换概率
- 相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
不过公式有些小的差别,那就是用句子的相似度类比于网页转移概率,用归一化的句子相似度代替了PageRank中相等的转移概率,这意味着在TextRank中,所有节点的转移概率不会完全相等。

TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
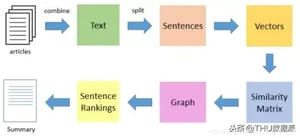
输出:
输出:
输出:
简要介绍一下word2vec模型参数含义
- sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
- size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
- window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
- sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
- negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
- cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
- min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
- iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
- alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
- min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
word2vec的训练:
输出:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/4735.html