
- 核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫
- 扩展部分(webmagic-extension)提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发
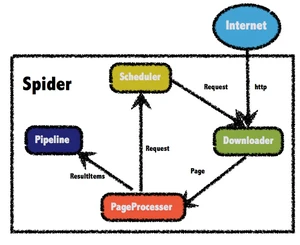
- Downloader:Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
- PageProcessor:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
- Scheduler:Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
- Pipeline:Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
- Request:Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
- Page:Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
- ResultItems:ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
- BilibiliReptile.java
- BiQuGeReptile.java
在0.7.3版本中,爬取只支持TLS1.2的https站点的时候会报错:
解决办法:https://github.com/code4craft/webmagic/issues/701
Scheduler是WebMagic中进行 URL 管理的组件。一般来说,Scheduler包括两个作用:
Scheduler的内部实现进行了重构,去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了三种去重方式。
布隆过滤器的使用实例:
指纹码对比
最常见的去重方案是生成文档的指纹门。例如对一篇文章进行 MD5 加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。
但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是重复的,这种方式并不合理。
BloomFilter
这种方式就是我们之前对 url 进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法 1 是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
KMP 算法
KMP 算法是一种改进的字符串匹配算法。KMP 算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一-样的,哪些不一样
这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的时空复杂度太高了,不适合大数据量的重复比对
SimHash (主要)
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前 Google 搜索引擎所目前所使用的网页去重算法
有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过 ip+时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的 WebMagic 可以很方便的设置爬取数据的时间(参考第二天的的 3.1. 爬虫的配置、启动和终止)。但是这样会大大降低我们 J 爬取数据的效率,如果不小心 ip 被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
代理 L(英语:Proxy),也称网络代理,是一-种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy. Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
我们就需要知道代理服务器在哪里(ip 和端口号)才可以使用。网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的还行。推荐个免费的服务网站:
配置代理
WebMagic的代理API ProxyProvider。因为相对于 Site 的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
- 设置代理:HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider)
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
代理示例:
设置单一的普通HTTP代理为101.101.101.101的8888端口,并设置密码为"username","password"
-
- Webmagic属于可快速上手的简易爬虫框架,在阅读官方文档后可快速上手开发,主要难点在于对于xpath(会正则的同学会很快就上手)的学习以及对于部分网站需要进行的cookie验证、代理以及登陆验证时有一定难度,对于部分动态渲染的前端页面可通过Chrome内核内嵌代码渲染的方式解决
PS:确实觉得写的很好,转给大家分享,文中提到的一些操作自己打算日后试试
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/4504.html