
语音是一个连续的音频流,它是由大部分的稳定态和部分动态改变的状态混合构成。

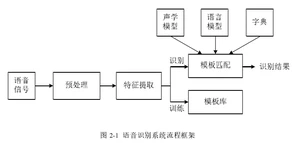
语音识别系统本质上属于模式识别系统的范畴,都包含有特征提取和模板识别.
机器在识别匹配过程中,将输入语音信号的特征与模板库中的特征参数进行对比,根据所选建模方式,找出与之最为相近的模板参数,最终得到识别结果。优化的结果与特征的选择、声学模型的好坏、模板的准确性都有直接的关系。
Sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。项目网址https://cmusphinx.github.io/
Sphinx家族全家福:

- Acoustic and Language Models:语音和语料模型,支持多种语言.
- Sphinxbase:核心库
- Sphinxtrain:生成用户自己语音语料模型的工具
- Pocketsphinx: PocketSphinx是一个计算量和体积都很小的嵌入式语音识别引擎。在Sphinx-2的基础上针对嵌入式系统的需求修改、优化而来,是第一个开源面向嵌入式的中等词汇量连续语音识别项目。识别精度和Sphinx-2差不多。
- Sphinx-2: 采用半连续隐含马尔可夫模型(SCHMM)建模,采用的技术相对落后,使得识别精度要低于其它的译码器。
- Sphinx-3: CMU高水平的大词汇量语音识别系统,采用连续隐含马尔可夫模型CHMM建模。支持多种模式操作,高精度模式扁平译码器,由Sphinx3的最初版本优化而来;快速搜索模式树译码器。目前将这两种译码器融合在一起使用。
- Sphinx-4: 是由Java语言编写的大词汇量语音识别系统,采用连续的隐含马尔可夫模型建模,和以前的版本相比,它在模块化、灵活性和算法方面做了改进,采用新的搜索策略,支持各种不同的语法和语言模型、听觉模型和特征流,创新的算法允许多种信息源合并成一种更符合实际语义的优雅的知识规则。由于完全采用JAVA语言开发,具有高度的可移植性,允许多线程技术和高度灵活的多线程接口。
pocketSphinx-python是sphinx的python版本.在github页面下(https://github.com/cmusphinx/pocketsphinx-python)
Pocketsphinx现在最新的版本是 5prealpha.下载安装文件后,解压.进入文件夹.,如果需要gstreamer支持,那么首先需要安装gstreamer, 然后再安装pocketsphinx.:https://cmusphinx.github.io/wiki/gstreamer/
https://pypi.org/project/pocketsphinx/
也可以安装pocketsphinx的python支持版本.首先下载所有的文件,包括sphinxbase和pocketsphinx.在安装时候需要首先安装上sphinxbase, pocketsphinx, 然后在pocketSphinx-python路径下输入:
Sphinx有两种模式:
- 一种是detect模式
- 一种是keyphrase模式.,以下是keyphrase模式的设置:
测试代码
参考博客: https://blog.csdn.net/zouxy09/article/details/
添加中文语言模型和中文声学模型
中文相关文件下载地址: https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/
- 声学模型:zh_broadcastnews_16k_ptm256_8000.tar.bz2
- 语言模型:zh_broadcastnews_64000_utf8.DMP
- 拼音字典:zh_broadcastnews_utf8.dic
拷贝到model文件夹下:
- 将文件放到PHTHON_HOME的pocketsphinx模块包下,我这里是在C:Python36Libsite-packagespocketsphinxmodel
放代码:没有变化,只是加载的目录文件变了。
通常,特别是针对指定词典库(.dic)和语言模型(lm)时,识别率通常都非常高. 对于识别率不高的情况, 可以从以下几方面改进:
- 采样率和声道. 音频解码时候的声道与录音时候的采样率和声道数不一致.
- 声学模型不一致.
- 语言模型不一致.语言模型应该就是lm模型.
- 词典和词语发音不一致. 也就是phonetic字典.:https://cmusphinx.github.io/wiki/tutorialtuning/
Lmtool: 语言模型库工具
创建解码器所必须的语言模型和词典模型. 当前的lmtool只能用于美式英语.
首先,创建一个Corpus.txt文件(名字可以任意). 在文件中放进需要语料信息(短语, 短句子, 词汇).
然后在这个网站里: http://www.speech.cs.cmu.edu/tools/lmtool-new.html
点击Choose file, 上传txt文件
点击Compile knowle base网站会自动生成.dic和语言.lm模型文件等一系列文件.下载其中的.tgz文件,并解压. 假设新生成的语言模型文件名为new_lm.lm, new_dic, 将这两个文件保存到 在代码中修改词典模型和语言模型, 如下, 就可以实现模型的更新. 更新后识别率确实提高了不少。
具体操作步骤
编辑一个自定义的keyword.txt文本,里面写入打算唤醒的中文词语,和发音可能混淆的词(如果拼音相同只记录一个就行)。再添加一些其他的乱七八糟的词,这样匹配的时候就不会一直匹配唤醒词了。(唤醒词的重点)。
在[http://www.speech.cs.cmu.edu/tools/lmtool-new.html] 上面训练上一步的keyword文本。会生成“随机数.lm”和“随机数.dic”,下载这两个文件就可以。用来替代语言模型和拼音字典。
王一蒙, 语音识别关键技术研究[D], 北京邮电大学
训练自己语料库的方法:
http://blog.csdn.net/x_r_su/article/details/
[*]这篇博客很有借鉴意义:
http://blog.csdn.net/x_r_su/article/details/
IRST LM Toolkit planning 构建大型语料库的工具
A toolkit for language modeling.
https://sourceforge.net/projects/irstlm/?source=typ_redirect
Cmusphinx bug讨论大汇总:
https://sourceforge.net/p/cmusphinx/bugs/
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.bianchenghao6.com/java-jiao-cheng/12432.html